Wazuh indexer tuning
This guide shows how to change settings to optimize the Wazuh indexer performance. To change the Wazuh indexer password, see the Password management section.
Memory locking
When the system is swapping memory, the Wazuh indexer may not work as expected. Therefore, it is important for the health of the Wazuh indexer node that none of the Java Virtual Machine (JVM) is ever swapped out to disk. To prevent any Wazuh indexer memory from being swapped out, configure the Wazuh indexer to lock the process address space into RAM as follows.
Note
You require root user privileges to run the commands described below.
Add the below line to the
/etc/wazuh-indexer/opensearch.ymlconfiguration file on the Wazuh indexer to enable memory locking:bootstrap.memory_lock: true
Modify the limit of system resources. Configuring system settings depends on the operating system of the Wazuh indexer installation.
Create a new directory for the file that specifies the system limits:
# mkdir -p /etc/systemd/system/wazuh-indexer.service.d/
Run the following command to create the
wazuh-indexer.conffile in the newly created directory with the new system limit added:# cat > /etc/systemd/system/wazuh-indexer.service.d/wazuh-indexer.conf << EOF [Service] LimitMEMLOCK=infinity EOF
Create a new directory for the file that specifies the system limits:
# mkdir -p /etc/init.d/wazuh-indexer.service.d/
Run the following command to create the
wazuh-indexer.conffile in the newly created directory with the new system limit added:# cat > /etc/init.d/wazuh-indexer.service.d/wazuh-indexer.conf << EOF [Service] LimitMEMLOCK=infinity EOF
Edit the
/etc/wazuh-indexer/jvm.optionsfile and change the JVM flags. Set a Wazuh indexer heap size value to limit memory usage. JVM heap limits prevent theOutOfMemoryexception if the Wazuh indexer tries to allocate more memory than is available due to the configuration in the previous step. The recommended value is half of the system RAM. For example, set the size as follows for a system with 8 GB of RAM.-Xms4g -Xmx4g
Where the total heap space:
-Xms4g- initial size is set to 4Gb of RAM.-Xmx4g- maximum size is to 4Gb of RAM.
Note
To prevent performance degradation due to JVM heap resizing at runtime, the minimum (Xms) and maximum (Xmx) size values must be the same.
Restart the Wazuh indexer service:
# systemctl daemon-reload # systemctl restart wazuh-indexer
Verify that the setting was changed successfully, by running the following command to check that
mlockallvalue is set totrue:# curl -k -u <INDEXER_USERNAME>:<INDEXER_PASSWORD> "https://<INDEXER_IP_ADDRESS>:9200/_nodes?filter_path=**.mlockall&pretty"
{ "nodes" : { "sRuGbIQRRfC54wzwIHjJWQ" : { "process" : { "mlockall" : true } } } }
If the output is
false, the request has failed, and the following line appears in the/var/log/wazuh-indexer/wazuh-indexer.logfile:Unable to lock JVM Memory
Shards and replicas
The Wazuh indexer offers the possibility of splitting an index into multiple segments called shards. Each shard is a fully functional and independent "index" that can be hosted on any node in the Wazuh indexer cluster. The splitting is important for two main reasons:
Horizontal scaling.
Distribution and parallelization operations across shards, increasing performance and throughput.
In addition, the Wazuh indexer allows users to make one or more copies of the index shards in what are called replica shards, or replicas for short. Replication is important for two reasons:
Provides high availability in case a shard or a node fails.
Allows the search volume and throughput to scale since searches can be executed on all replicas in parallel.
Number of shards for an index
Before creating the first index, consider carefully how many shards will be needed. It is not possible to change the number of shards without re-indexing.
The number of shards needed for optimal performance depends on the number of nodes in the Wazuh indexer cluster. As a general rule, the number of shards must be the same as the number of nodes. For example, a cluster with three nodes should have three shards, while a cluster with only one node would only need one.
Number of replicas for an index
The number of replicas depends on the available storage for the indices. Here is an example of how a Wazuh indexer cluster with three nodes and three shards could be set up.
No replica: Each node has one shard. If one node goes down, an incomplete index of only two shards is available.
One replica: Each node has one shard and one replica. If one node goes down, a full index is still available.
Two replicas: Each node has the full index with one shard and two replicas. With this setup, the cluster continues to operate even if two nodes go down. Although this seems to be the best solution, it increases the storage requirements.
The image below shows a Wazuh indexer cluster with three nodes, each containing a primary shard and two replica shards.
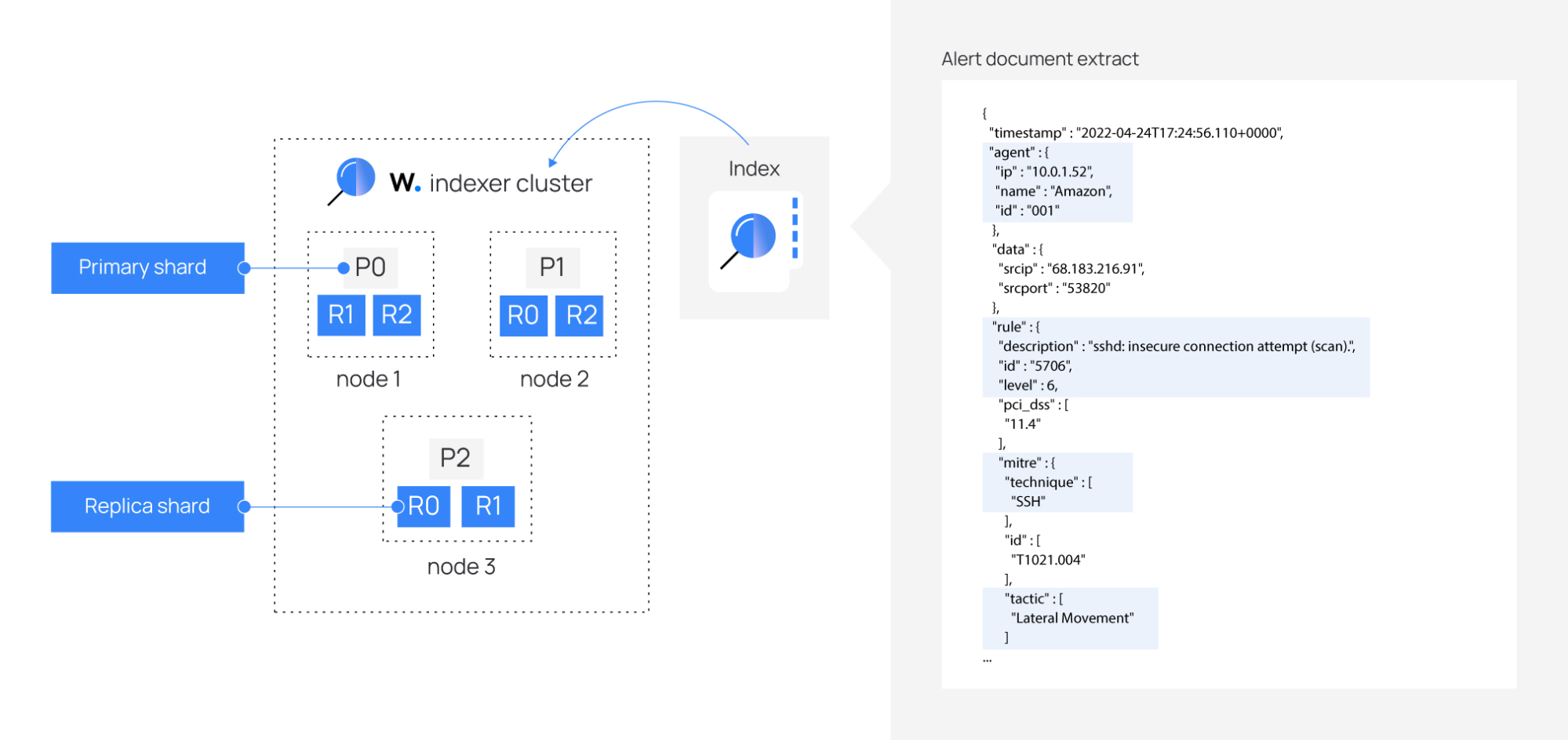
Setting the number of shards
Note
The number of shards and replicas are defined per index at the time of index creation. Once the index is created, although the number of replicas can be changed dynamically, the number of shards cannot be changed without re-indexing.
The default installation of a Wazuh indexer node creates each index with three primary shards and no replicas. You can modify the number of primary shards and replicas by loading a new template using the Wazuh API.
In the following example, we set the number of shards for a single-node Wazuh indexer to 1. Perform the following steps on the Wazuh indexer node or any central component allowed to authenticate using the Wazuh API.
Download the Wazuh indexer template:
# curl https://raw.githubusercontent.com/wazuh/wazuh/v4.14.6/extensions/elasticsearch/7.x/wazuh-template.json -o w-indexer-template.json
Edit
w-indexer-template.jsonto setindex.number_of_shardsto1. To avoid Filebeat overwriting the existing template, set theorderto1. Multiple matching templates in the same order result in a non-deterministic merging order.{ "order": 1, "index_patterns": [ "wazuh-alerts-4.x-*", "wazuh-archives-4.x-*" ], "settings": { "index.refresh_interval": "5s", "index.number_of_shards": "1", "index.number_of_replicas": "0", "index.auto_expand_replicas": "0-1", "index.mapping.total_fields.limit": 10000, ...Load the new settings.
# curl -X PUT "https://<INDEXER_IP_ADDRESS>:9200/_template/wazuh-custom" -H 'Content-Type: application/json' -d @w-indexer-template.json -k -u <INDEXER_USERNAME>:<INDEXER_PASSWORD>
{"acknowledged":true}Confirm that the configuration was successfully updated.
# curl "https://<INDEXER_IP_ADDRESS>:9200/_template/wazuh-custom?pretty&filter_path=wazuh-custom.settings" -k -u <INDEXER_USERNAME>:<INDEXER_PASSWORD>
{ "wazuh-custom" : { "settings" : { "index" : { "mapping" : { "total_fields" : { "limit" : "10000" } }, "refresh_interval" : "5s", "number_of_shards" : "1", "auto_expand_replicas" : "0-1", "number_of_replicas" : "0", ...
If the index has already been created, it must be re-indexed.
Setting the number of replicas
The number of replicas can be changed dynamically using the Wazuh indexer API. In a single-node cluster, the number of replicas should be set to zero. This is accomplished by running the following command on the Wazuh indexer node or any central component allowed to authenticate using the Wazuh API:
curl -k -u "<INDEXER_USERNAME>:<INDEXER_PASSWORD>" -XPUT "https://<INDEXER_IP_ADDRESS>:9200/wazuh-alerts-" -H 'Content-Type: application/json' -d'
{
"settings": {
"index": {
"number_of_replicas": 0
}
}
}'