Basics
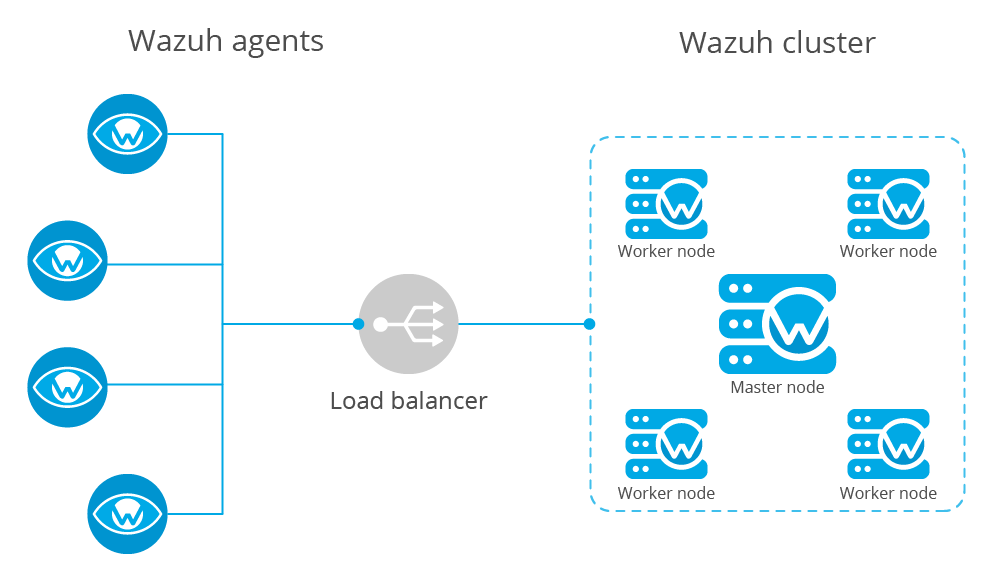
A Wazuh cluster is a group of Wazuh managers that work together to enhance the availability and scalability of the service. With a Wazuh cluster setup, we have the potential to greatly increase the number of agents as long as we add worker nodes whenever necessary.
Reasons for using a cluster
Horizontal scalability
It multiplies Wazuh's event processing capacity and allows it to have thousands of agents reporting. Adding a new node to the cluster is very simple (just add the master's address in the configuration) and it can be automated easily, giving the user the ability to implement auto-scaling.
High availability
Servers eventually fail: hardware can be broken, a human can turn them off, the system can go down... And while the server is restored, you won't be able to see what is happening in your agents. Using a cluster you make sure your agents will always have a manager to report to.
Types of nodes
Master
The master node centralizes and coordinates worker nodes, making sure the critical and required data is consistent across all nodes. It provides the centralization of the following:
Agent registration.
Agent deletion.
Rules, decoders and CDB lists synchronization.
Configuration of agents grouping.
Warning
The master doesn't send its local configuration file to the workers. If the configuration is changed in the master node, it should be changed manually in the workers. Take care of not overwriting the cluster section in the local configuration of each worker.
Warning
When rules, decoders or CDB lists are synchronized, the worker nodes are not restarted. They must be restarted manually in order to apply the received configuration.
All communications among nodes in the cluster are encrypted using AES algorithm.
Worker
Worker nodes are responsible of two main tasks:
Synchronizing integrity files from the master node.
Sending agent status updates to the master.
How the cluster works
The cluster is managed by a daemon, called wazuh-clusterd, which communicates with all the nodes following a master-worker architecture. Refer to the Daemons section for more information about its use.
The image below shows the communications between a worker and a master node. Each worker-master communication is independent from each other, since workers are the ones who start the communication with the master.
There are different independent threads running, each one is framed in the image:
Keep alive thread: Responsible of sending a keep alive to the master every so often.
Agent info thread: Responsible of sending the statuses of the agents that are reporting to that node.
Integrity thread: Responsible of synchronizing the files sent by the master.
All cluster logs are written in the file
logs/cluster.log.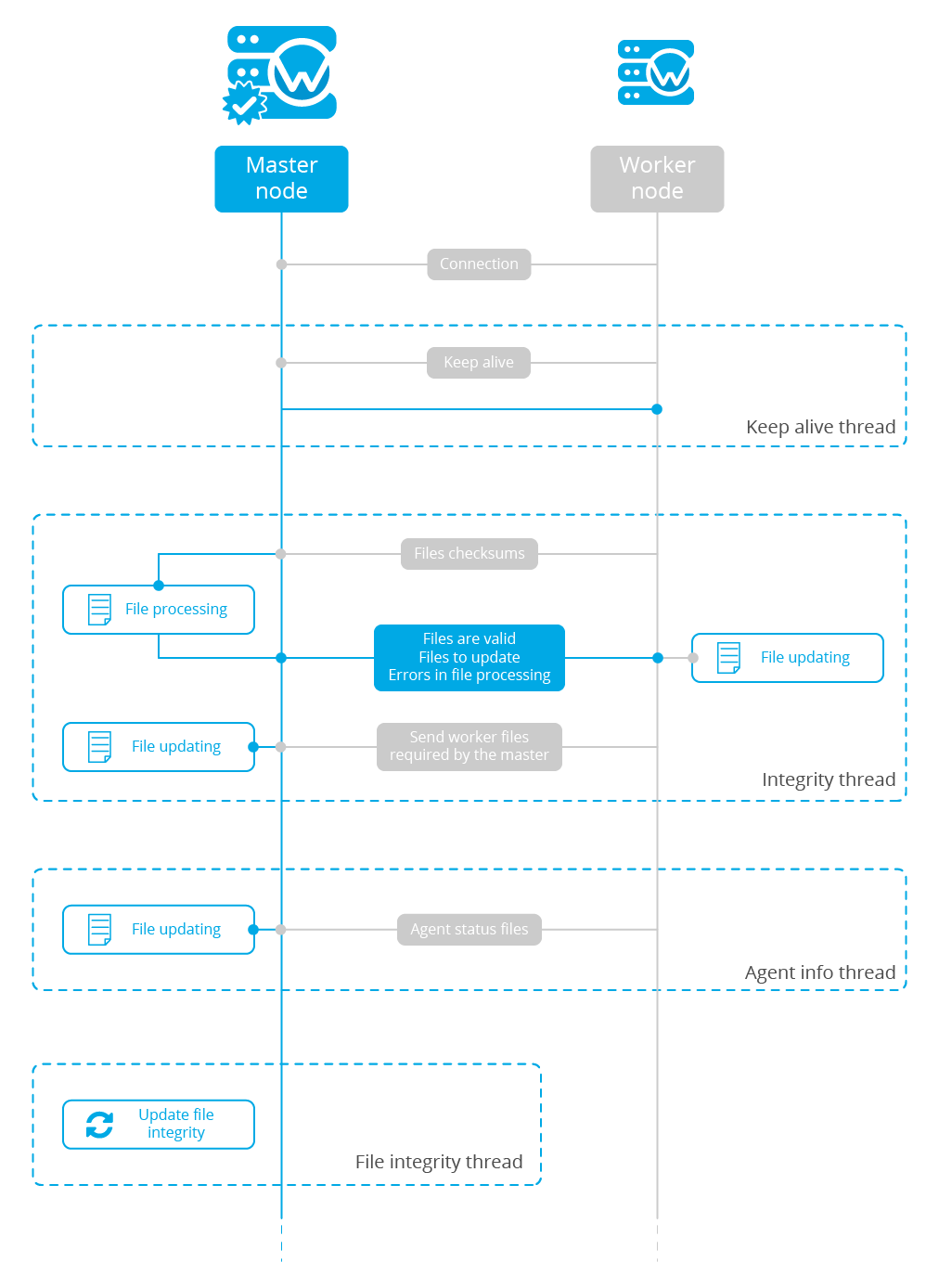
Keep alive thread
The keep alive thread sends a keep-alive to the master every so often. It is necessary to keep the connection opened between master and worker, since the cluster uses permanent connections.
Agent info thread
The agent info thread sends the statuses of the agents that are reporting to the worker node. The master checks the modification date of each received agent status file and keeps the most recent one.
The master also checks whether the agent exists or not before saving its status update. This is done to prevent the master to store unnecessary information. For example, this situation is very common when an agent is removed but the master hasn't notified worker nodes yet.
Integrity thread
The integrity thread is in charge of synchronizing the files sent by the master node to the workers. Those files are:
Usually, the master is responsible for sending group assignments, but just in case a new agent starts reporting in a worker node, the worker will send the new agent's group assignment to the master.
File Integrity Thread
The integrity of each file is calculated using its MD5 checksum and its modification time. To avoid calculating the integrity with each worker connection, the integrity is calculated in a different thread, called File integrity thread, in the master node every so often.