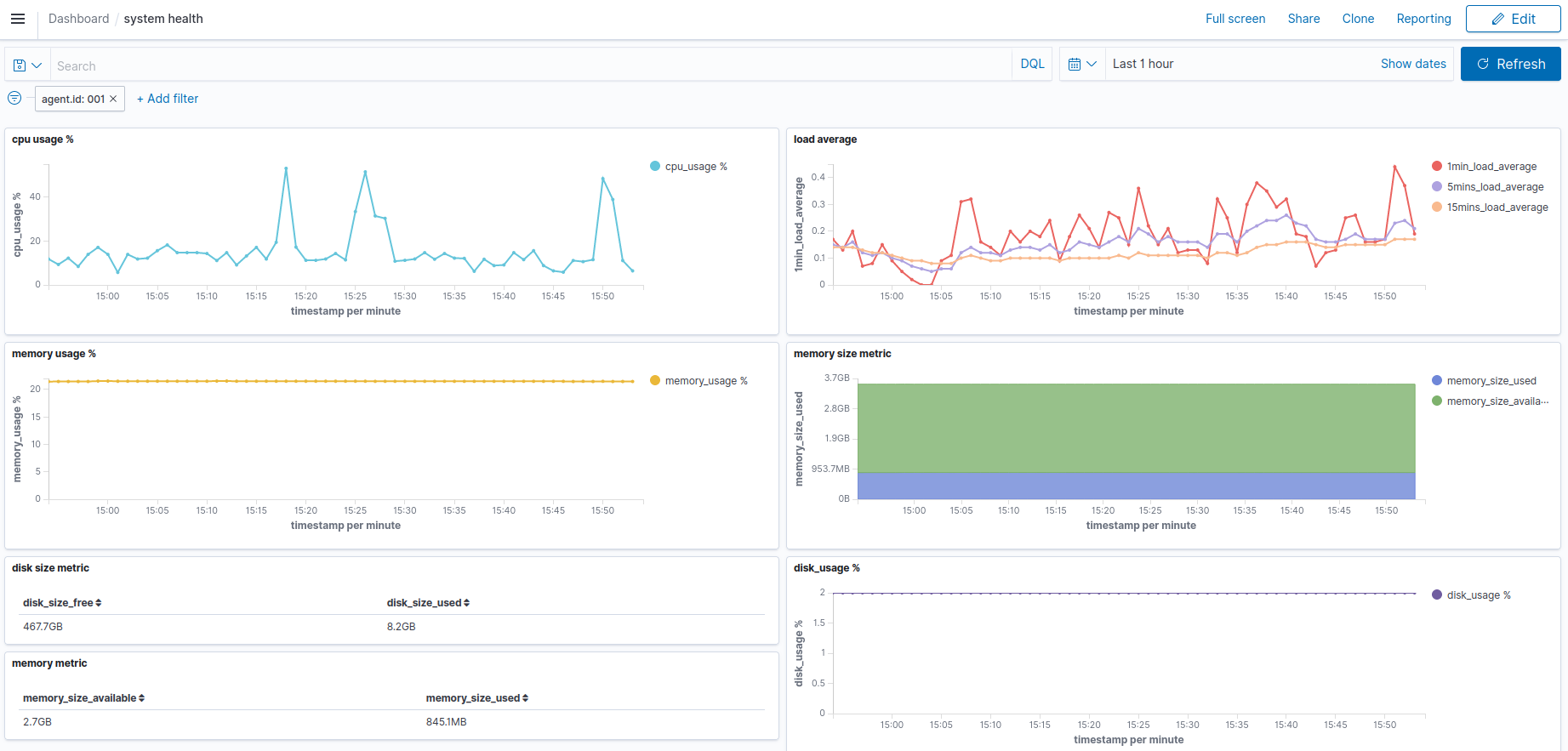
Creating custom dashboards
This section describes the process of creating a set of custom visualizations using the Wazuh dashboard component. We also show how to add individually created visualizations together to create a custom dashboard.
Visualizing the data
Data visualization enhances the ability to comprehend complex security data by providing a visual representation. This representation can reveal patterns, trends, anomalies, and insights more effectively than raw data alone. This simplifies the interpretation of large datasets and makes it easier to identify security threats, assess the overall state of security, and make informed decisions.
There are different visualization techniques that can help make data clear and appealing. The Wazuh Visualize page takes data from the Discover page and turns it into various visual types like Bar, Area, Line Charts, Pie Charts, Maps, and Tables. These visuals can be saved, combined for dashboards, and shared with others using the Wazuh dashboard.
We will cover the practical aspect of dashboard creation by creating different types of visualizations in the Wazuh dashboard and then integrate the visualizations to create a custom dashboard.
Creating visualizations
To create a visualization, click the upper-left menu icon and navigate to OpenSearch Dashboards > Visualize. This action will open a page where a list of visualizations is displayed if any have already been created. If not, the page will show a Create new visualization button in the middle.
Next, we must select the visualization type from the New Visualization screen. This screen presents various visualization types, as shown below:
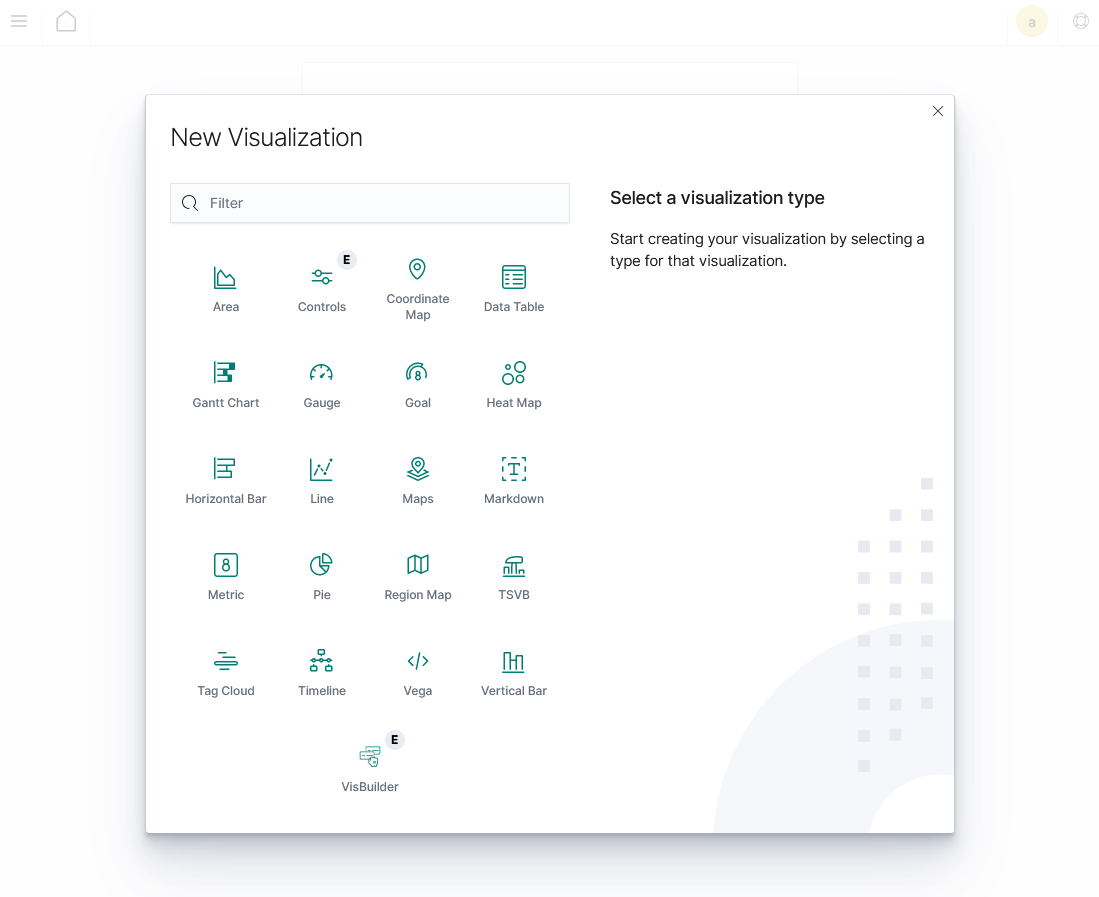
Choose the visualization option that best suits your data by clicking on the visualization type box. Here, we selected the Area chart visualization.
After selecting the visualization type, for most of the visualization types, the next step is to choose the desired index to work with. This will be the data source that the visualization will be built on. The visualization type selected will redirect you to the screen displayed below.
Wazuh dashboard aggregation
The Wazuh dashboard visualization contains two main aggregation objects;
Metric aggregation.
Bucket aggregation.
Metric aggregation
Metric aggregation calculates metrics by aggregating data values. This contains the actual values of the metric to be calculated. Metric aggregation is typically represented on the Y-axis.
There are different types of metric aggregations as shown below:
Average: This is the average of a numeric field. It calculates the arithmetic mean of an existing set of data values. The Average is obtained by adding up all the data values and dividing its sum by the total count.
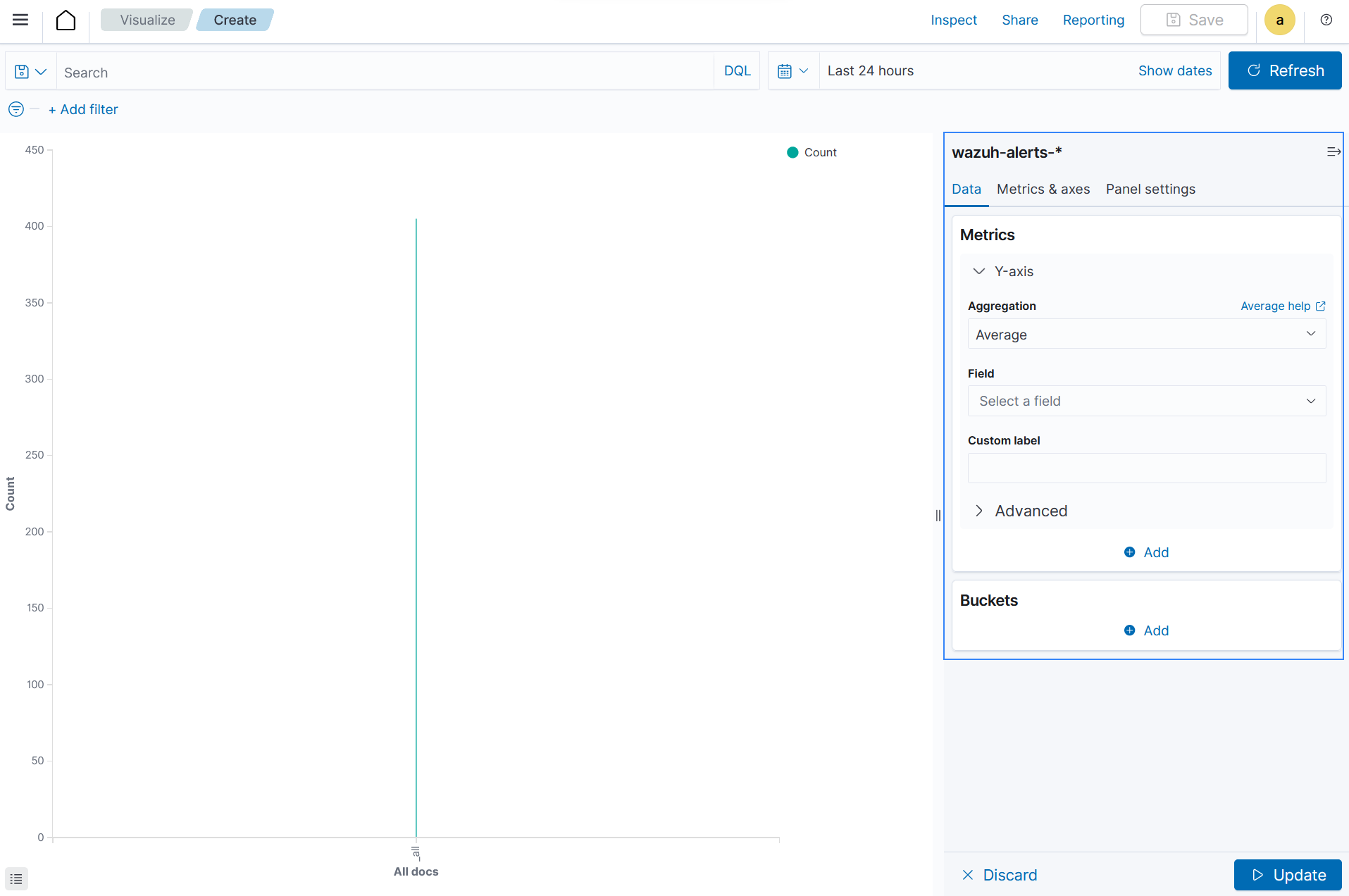
Average aggregation helps in calculating the average duration of security incidents, average severity score of alerts, average response time to resolve incidents and more.
Count: This is the number of data values that match a query within the selected index pattern. It counts the number of data points in a set and provides the total count of a queried event.
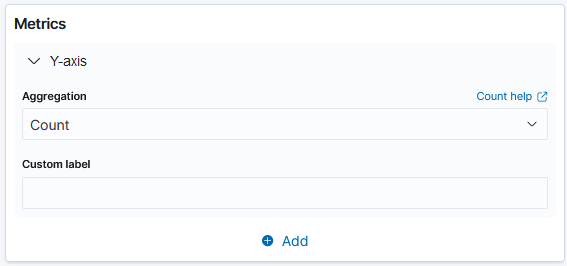
Count aggregation helps in determining the total number of security events, number of alerts triggered by a specific rule, the number of failed login attempts and more.
Max: This is the maximum value of a numeric field within a selected index pattern. Max identifies the highest value among a group of values.
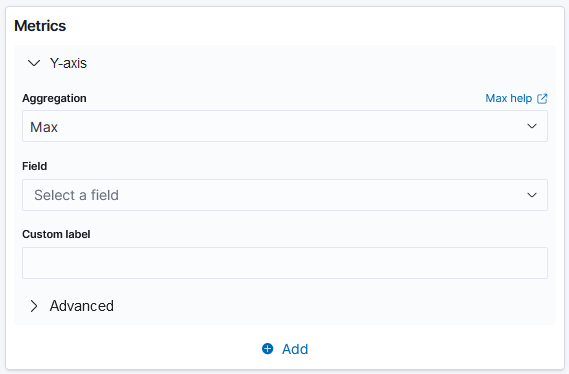
Max aggregation helps in identifying the maximum severity level of alerts, maximum CPU usage, the maximum number of failed login attempts within a given timeframe and more.
Median: This is the median value in a numeric field. Median determines the middle value in a sorted set of values within a selected index pattern by separating the higher half from the lower half of the data.
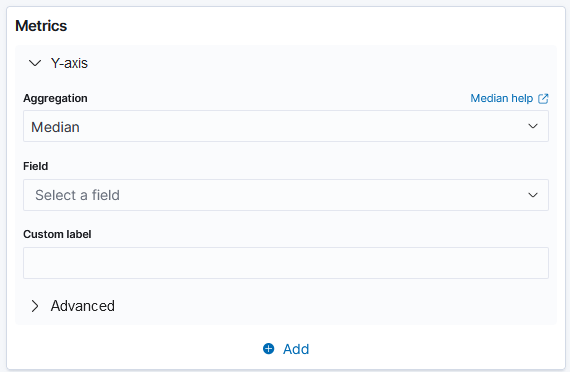
Median aggregation helps to provide the middle value of event durations, helping to identify the typical or median response time.
Min: This is the minimum value in a numeric field set. Min identifies the lowest value among a group of values.
Min aggregation helps in determining the minimum severity level of alerts, minimum disk space usage, the minimum number of successful logins and more.
Percentile Ranks: This is the ranking for values within a given numeric field in percentile. Percentile rank calculates the percentage of values below a specific value in a set and expresses how a given value compares to the distribution of the data.
Percentile rank aggregation helps in assessing the relative severity of alerts in comparison to the entire dataset. This determines the percentile rank of a specific severity score.
Percentile: This aggregation changes numeric field values into percentile bands. Percentile identifies specific data values that correspond to specific percentiles. For example, the 90th percentile represents the value below which 90% of the data falls.
Standard Deviation: This measures the amount of variation in a set of numeric field values. It evaluates the average distance between each value and the mean value.
Standard deviation aggregation can help identify changes in event durations. This provides insights into the volatility or stability of security events.
Sum: This is the total sum of a numeric field. Sum calculates the total sum of a set of values by adding up all the values in the dataset within a selected index pattern.
Sum aggregation helps in determining the total count of specific event types, the total number of successful logins, the total disk space used and more.
Top Hit: This aggregation identifies the top data point based on a specified criteria or sort order. Top hit is commonly used to extract specific information from the dataset based on the top metric.
Top hit aggregation helps in extracting key information from security events, such as retrieving the most recent log entry for a particular host or user.
Unique Count: This is the count of unique values within a designated field. It counts the number of unique or distinct values in a set. Unique count disregards any duplicate event and provides the count of unique values.
Unique count aggregation helps in determining the number of distinct IP addresses accessing a system, the number of unique users triggering alerts, the count of unique event types and more.
Parent Pipeline Aggregations
Cumulative Sum: This is the calculation of the running sum of a metric across a specified set of data points. It shows the progressive total as each data point is added.
Cumulative sum aggregation can be used to track the total count of security events over time, providing insights into the cumulative impact of incidents.
Derivative: This is the calculation of the rate of change of values over time. Derivative is the difference between consecutive values in a time series or dataset.
Derivative aggregation helps in calculating the rate of change in event counts or severity scores. This enables the detection of sudden spikes or anomalies.
Moving Avg: This is the calculation of the average of a metric over a moving window of data points. It provides a neat representation of the data, hence reducing noise or fluctuations.
Moving average aggregation helps in smoothing out fluctuations in event counts or resource usage, enabling trend analysis or anomaly detection.
Serial Diff: This is the difference between consecutive values in a time series or ordered dataset. It measures the absolute change from one data point to the next.
Serial diff aggregation helps in identifying the difference in event counts or resource usage between consecutive data points, showing changes or trends.
Sibling Pipeline Aggregations
Average Bucket: This is the average value of a metric within each bucket of a specified aggregation. Average bucket provides the average value per group or category.
Average bucket aggregation helps in calculating the average severity score or event count within specific time intervals or categories.
Max Bucket: This is the maximum value of a metric within each bucket of a specified aggregation. It identifies the highest value per group.
Max bucket aggregation enables the identification of the maximum severity level or event count within specific time intervals or categories.
Min Bucket: This is the minimum value of a metric within each bucket of a specified aggregation. It identifies the lowest value per group or category.
Min bucket aggregation helps identify the minimum severity level or event count within specific time intervals or categories.
Sum Bucket: This is the total sum of a metric within each bucket of a specified aggregation. It adds up the values per group.
Sum bucket aggregation helps in calculating the total count or severity score within specific time intervals or categories.
Bucket aggregation
This is used to determine the type of information we are trying to get from the dataset. The bucket aggregation determines how the data is segmented or grouped such as by date. It is typically represented on the X-axis.
These are the following types of bucket aggregations for a pie chart:
Date Histogram: This aggregation is used to display a numeric field and organize that using the date.
Date Range: This aggregation is used to report the values within a date range which we can specify.
Filters: This aggregation is used to apply filters on data.
Histogram: This aggregation is used for numeric fields, where we can provide the integer interval for the selected field.
IPv4 Range: This aggregation provides us with the option to set the range using IPv4 addresses.
Range: This aggregation is used to provide the range of numeric field values.
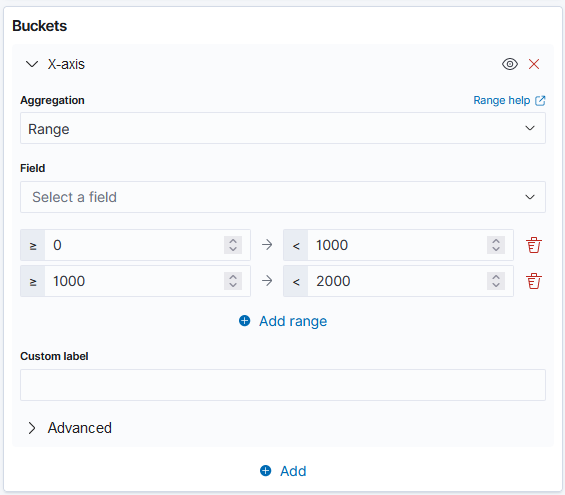
Significant Terms: This aggregation returns interesting or unusual occurrences of terms in a set.
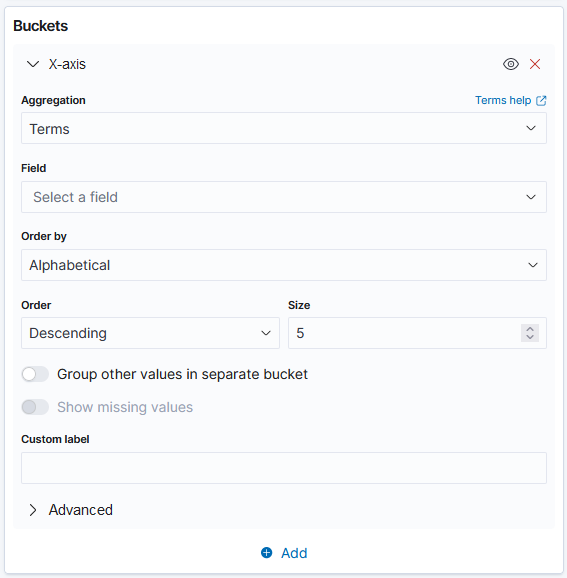
Terms: This aggregation enables us to pick the top or bottom n elements of the selected field.
Both the Y-axis and the X-axis are used to plot the data points on a visualization chart.
Basic charts
The following is a list of the basic charts for visualization:
Bar, area, and line charts: These charts are used for comparing different series in x and y axis.
Pie charts: These charts are used when all of the fields are related to each other; for example, the voting percentage for different parties in an election.
Heat maps: These are used to shade the cells within a matrix.
Bar charts
Bar charts are a type of visualization that are used to compare specific measures for different data categories. These are the most common type of visualization, and are easy to create and interpret. Bar charts are used to present categorical data in the form of rectangular bars with heights/lengths that are proportional to the given values.
Creating a Bar chart
Horizontal Bar: This is a type of bar chart where rectangular bars are displayed horizontally. The length or width of each bar corresponds to a particular value. This allows an easy comparison between different data points. Horizontal bar charts are often used to visualize data that has distinct categories or to show rankings.
From the Visualize tab, click Create Visualization, select the
Horizontal barvisualization format and usewazuh-alerts-*as the index pattern name.
In the
Datasection, on theY-axisof Metrics, set the following value:Aggregation=Count
Add a
X-axisin Bucket and set the following values:Aggregation=TermsField=rule.mitre.tacticOrder by=Metric: CountOrder=DescendingSize=10
Click the Update button.
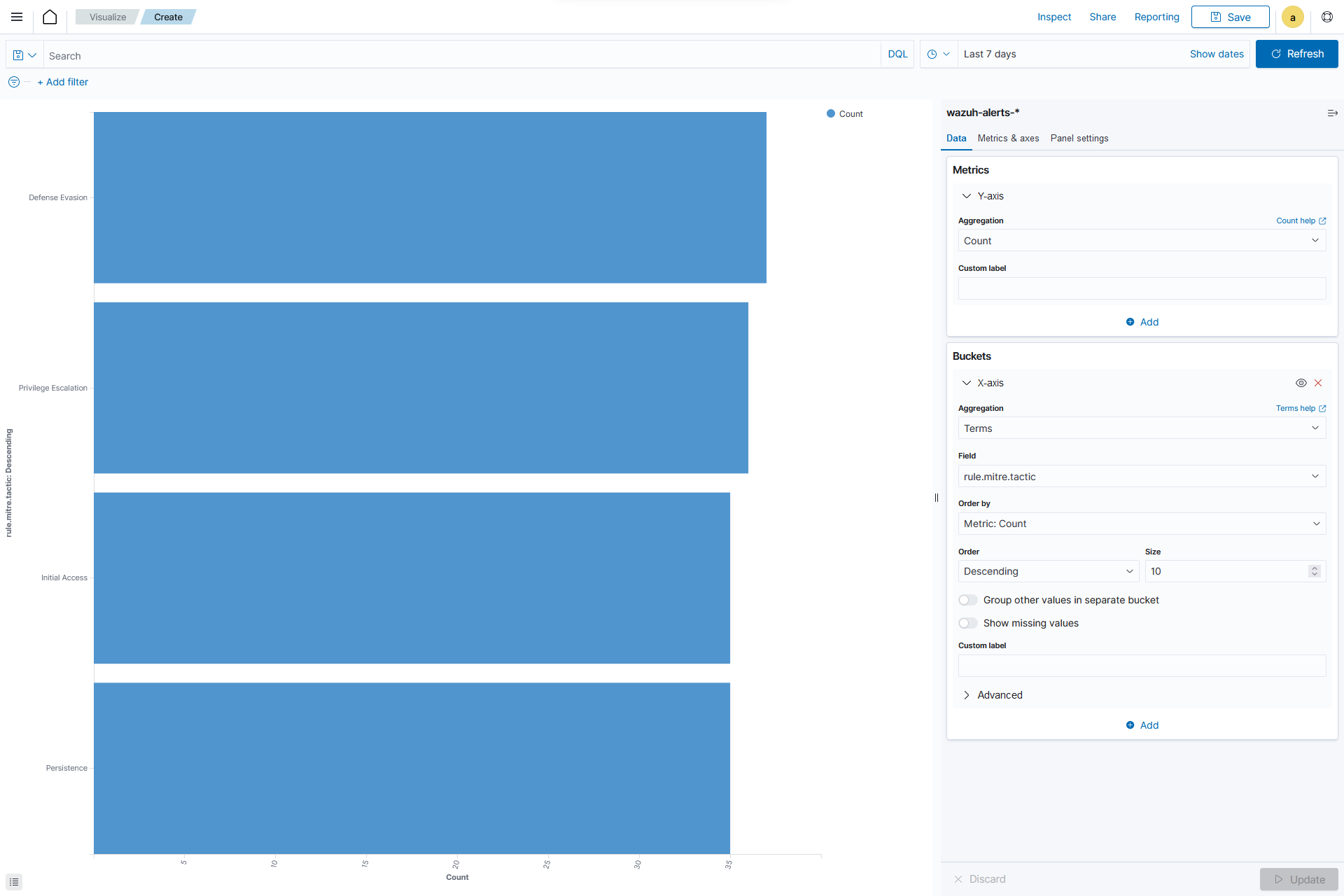
Click the upper-right Save button and assign a title to save the visualization.
Vertical Bar: This is a type of bar chart where the bars are displayed vertically, with the length or height of each bar representing a particular value. Vertical bar charts are suitable for comparing data across different categories. They are commonly used to display rankings, comparisons, or distribution of values.
From the Visualize tab, select the
Vertical Barvisualization format and usewazuh-alerts-*as the index pattern name.
In the
Datasection, on theY-axisof Metrics, set the following value:Aggregation=Count
Add a
X-axisin Bucket and set the following values:Aggregation=TermsField=rule.mitre.tacticOrder by=Metric: CountOrder=DescendingSize=10
Click the Update button.
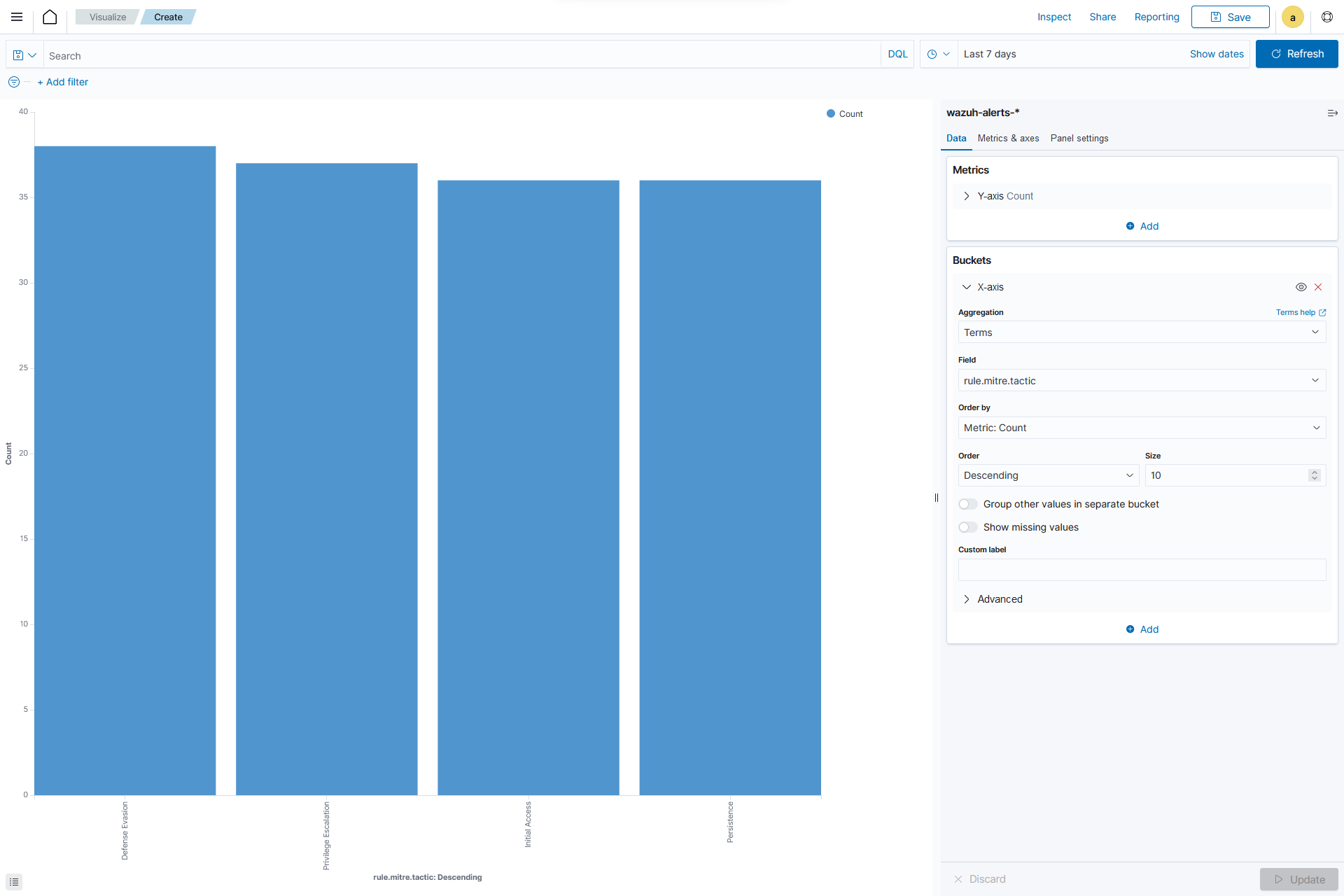
Click the upper-right Save button and assign a title to save the visualization.
Pie charts
This is a circular chart that is divided into sectors, with each sector representing a percentage of a whole data set. They are commonly used to show market share, composition of data, or distribution of categories.
The total slice size of a pie chart is calculated by the metrics aggregation. In the case of a pie chart, we use the count, sum, unique count.
Creating a Pie chart
From the Visualize tab, click Create Visualization, select the
Pievisualization format and usewazuh-alerts-*as the index pattern name.
In the
Datasection, on theSlice sizeof Metrics, set the following value:Aggregation=Count
Add a
Split slicesin Bucket and set the following values:Aggregation=TermsField=rule.mitre.tacticOrder by=Metric: CountOrder=DescendingSize=10
In the
Optionssection, customize the Pie chart by toggling onshow label.Click the Update button.
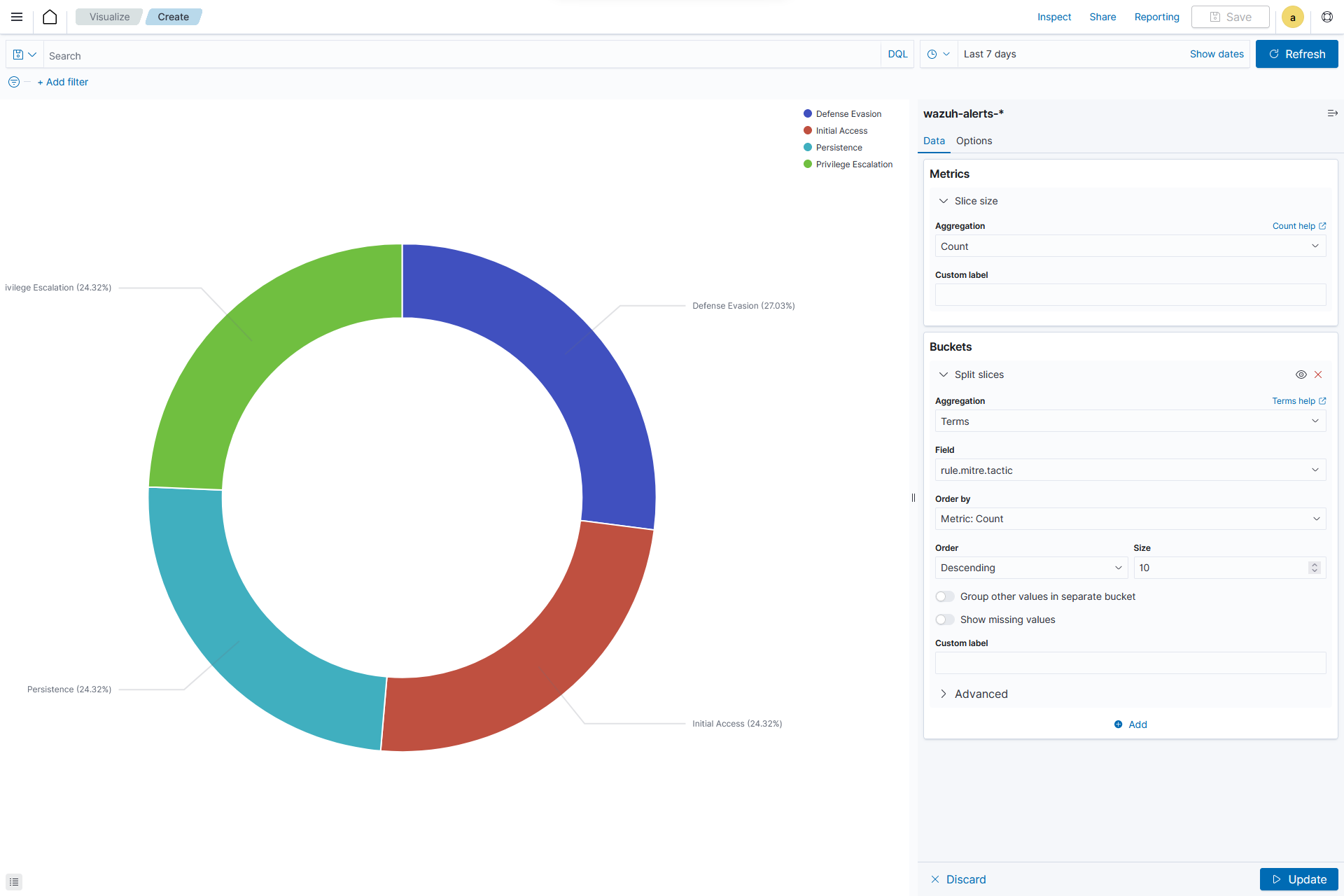
Click the upper-right Save button and assign a title to save the visualization.
Area charts
This is used to display graphically quantitative data using filled-in areas. The areas between axes and lines are typically filled with colors or patterns to differentiate between different categories or data points. This emphasizes the quantity beneath a line chart.
Area charts are useful for showing the magnitude and distribution of data over time or categories. They are often used to display trends, comparisons, or cumulative values.
Creating a Area chart
From the Visualize tab, click Create Visualization, select the
areavisualization format, and usewazuh-alerts-*as the index pattern name.
On the
Y-axisof Metrics, set the following values:Aggregation=MaxField=data.memory.used_bytes
Add another
Y-axisin Metric and set the following values:Aggregation=MaxField=data.memory.available_bytes
Add an
X-axisin Bucket and set the following values:Aggregation=Date HistogramField=timestamp
Click the Update button.
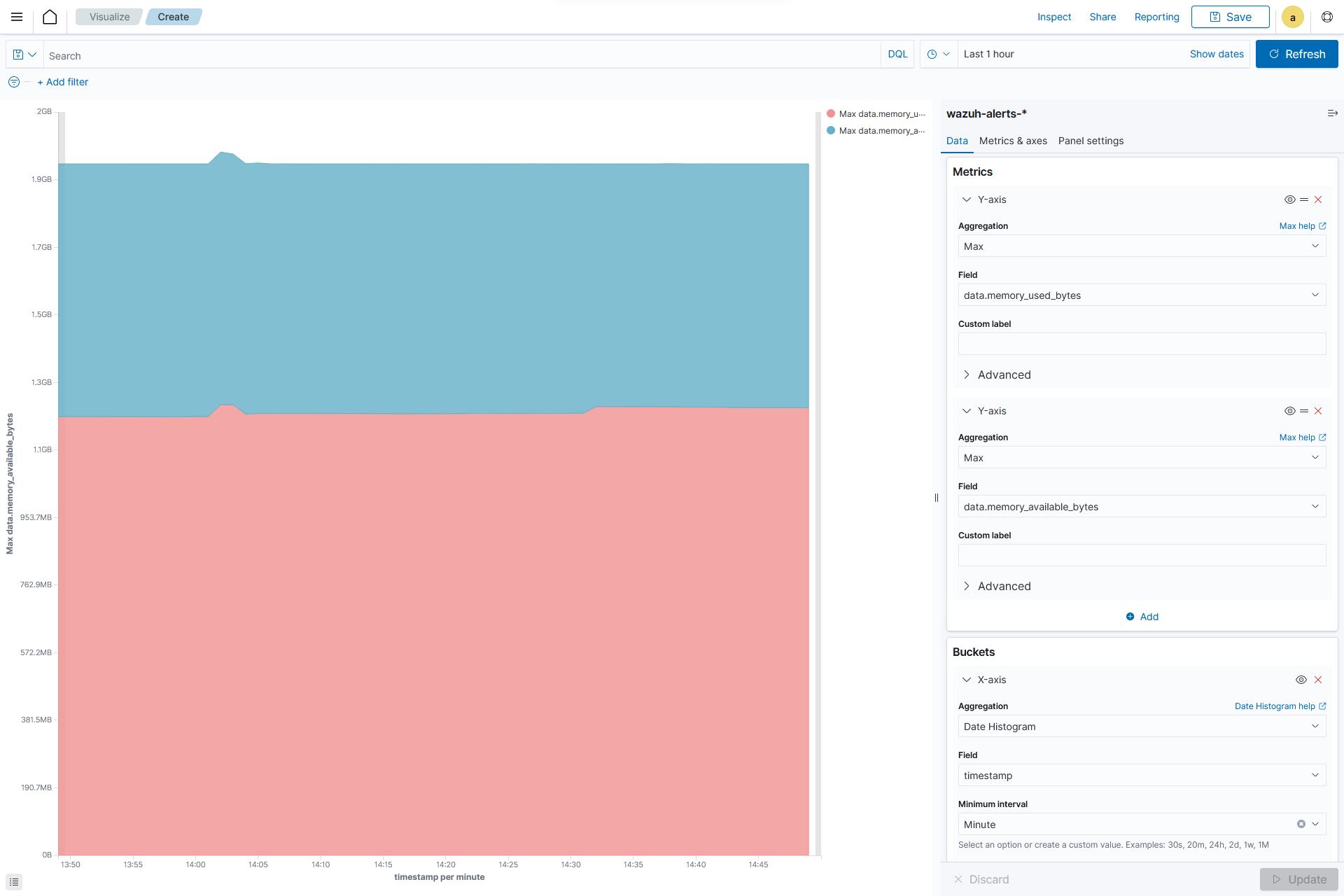
Click the upper-right Save button and assign a title to save the visualization.
Line charts
This visualization represents data points connected by straight lines. It is commonly used to display trends, patterns, relationships over time or a continuous range. By plotting data along a Cartesian coordinate system, lines are drawn to connect the data points. This provides a clear depiction of how the values change.
Creating a Line chart
From the Visualize tab, click Create Visualization, select the
Linevisualization format and usewazuh-alerts-*as the index pattern name.On the
Y-axis, in Metrics, set the following values:Aggregation=MaxField=data.memory.usage_%
Add an
X-axisin Buckets and set the following values:Aggregation=Date HistogramField=timestampMinimum interval=Minute
Click the Update button.
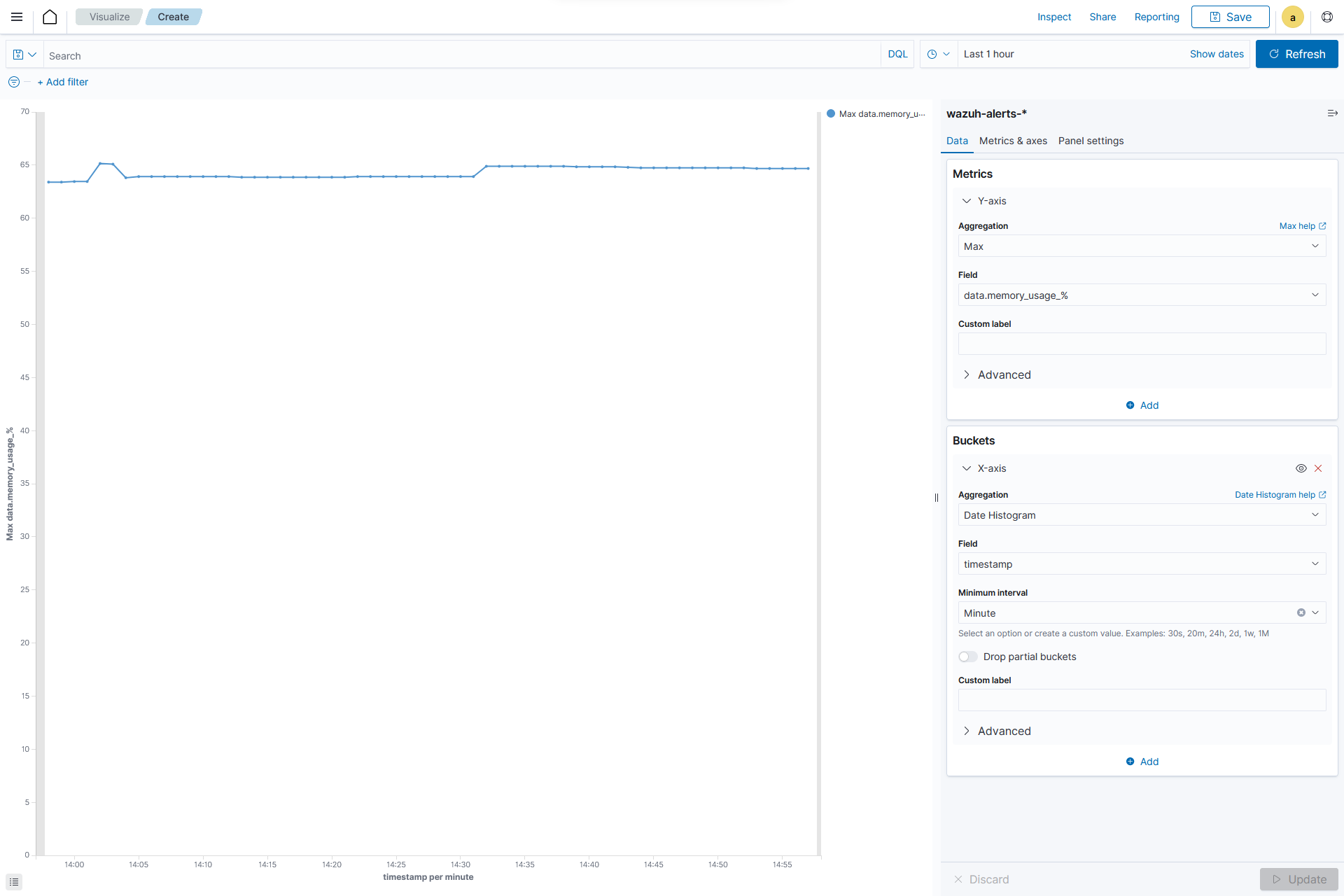
Click the upper-right Save button and assign a title to save the visualization.
Heat maps
This is a graphical representation that uses colors to visualize the density of certain variables. Heat maps display data points as colored cells, with each color representing a different value or level of intensity.
Heat maps are useful for identifying patterns, trends, or variations within a dataset.
Creating a Heat Map
From the Visualize tab, click Create Visualization, select the
Heat Mapvisualization format and usewazuh-alerts-*as the index pattern name.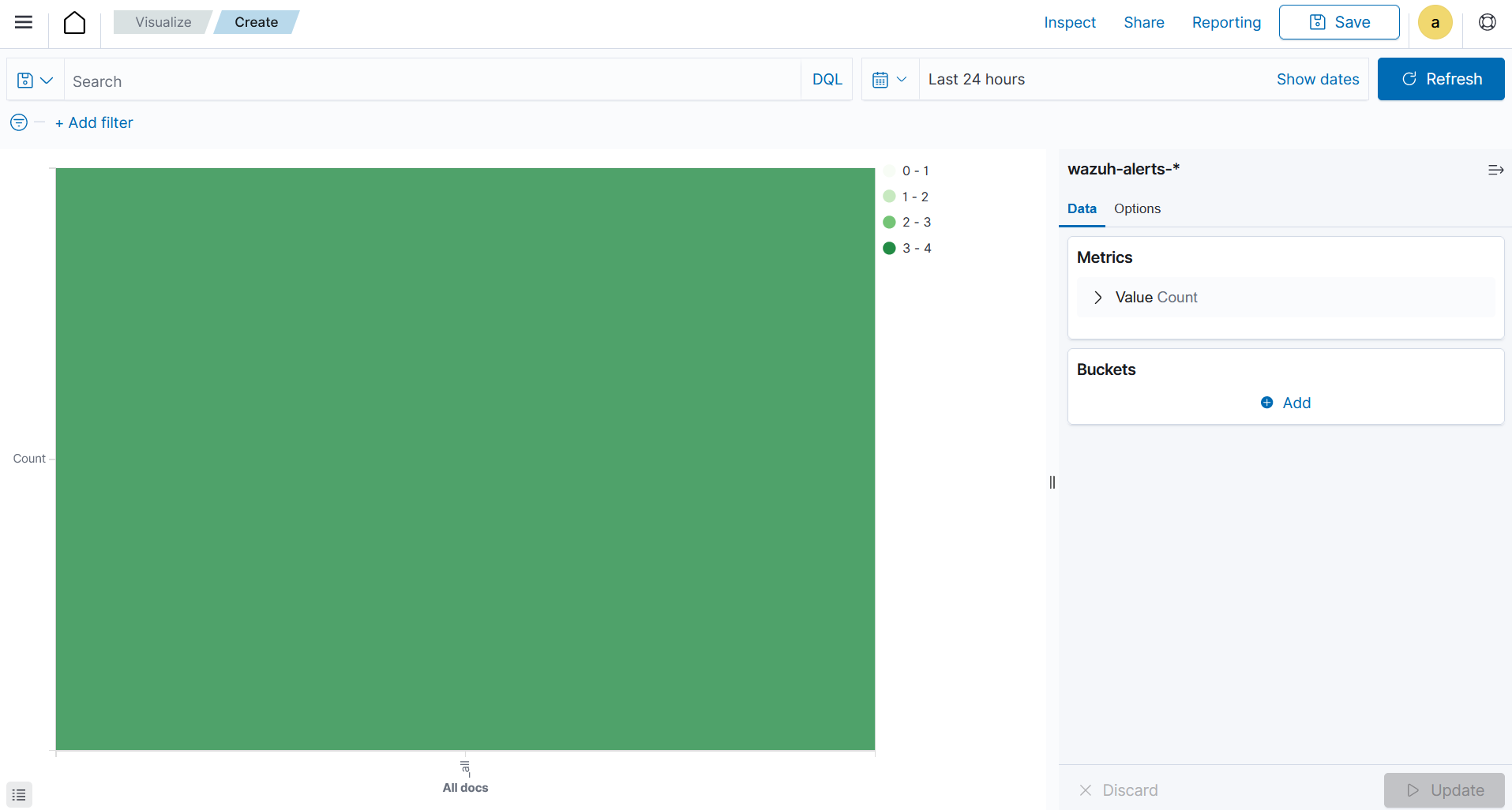
On the
Y-axis, in Metrics, set the following value:Aggregation=Count
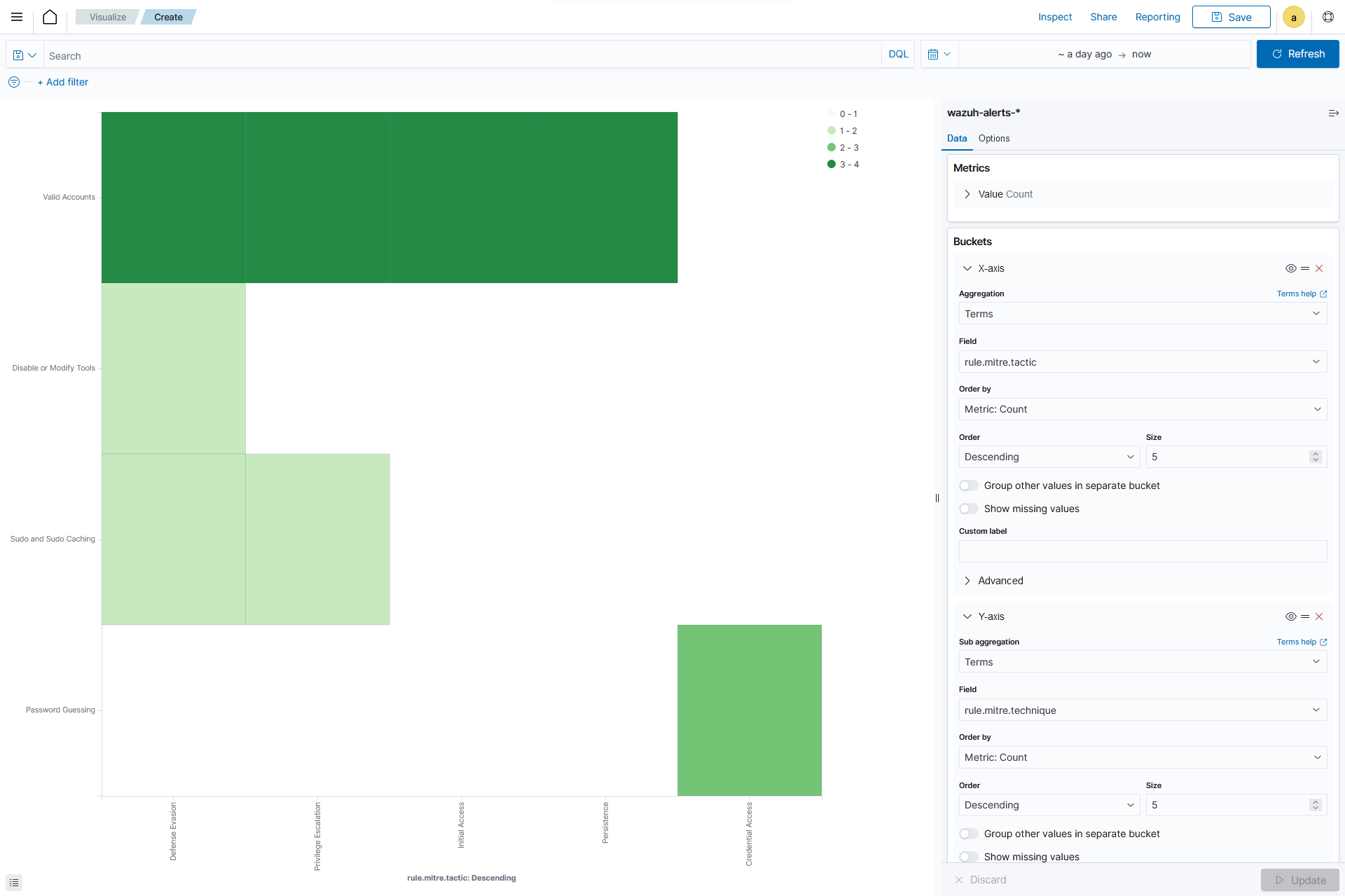
Add an
X-axisin Buckets and set the following values:Aggregation=TermsField=rule.mitre.tacticOrder by=Metric: CountOrder=DescendingSize=5
Add a
Y-axisin Buckets and set the following values:Aggregation=TermsField=rule.mitre.techniquesOrder by=Metric: CountOrder=DescendingSize=5
Click the Update button.
Data
Data metric visualization is a single number that displays any count or calculation.
The following is a list of data visualizations:
Data table: This is where the data is shown in tabular form.
Metric: This is where a single number is displayed, which we can use to show any important metric data.
Goal and gauge: This is used when we want to display any progress.
Data table
This is a tabular representation of data that is organized into rows and columns. It provides a structured format to display and analyze data. Each row represents a specific entry, and each column represents a different variable. Data tables are widely used for data analysis, reporting, and providing a clear overview of multiple variables.
Creating a Data table
From the Visualize tab, click Create Visualization, select the
Data Tablevisualization format and usewazuh-alerts-*as the index pattern name.On the Metric in Metrics data, set the following values:
Aggregation=MaxField=data.disk_used_bytes
Add an additional metric
Aggregation=MaxField=data.disk_free_bytes
Click the Update button.
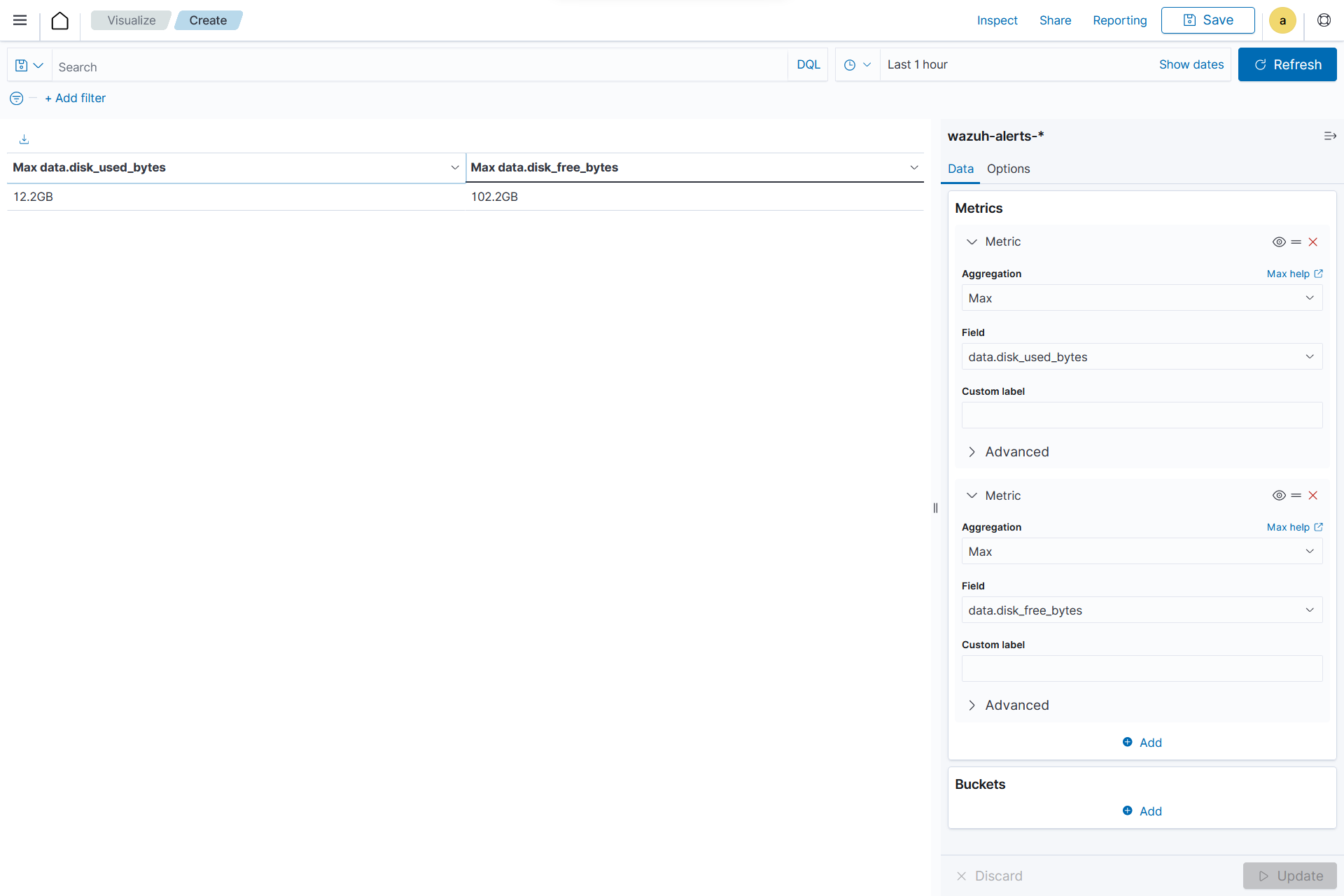
Click the upper-right Save button and assign a title to save the visualization.
Metric
This is a quantifiable measurement that is used to evaluate performance, progress, or specific characteristics. Metric represents a calculation as a single numerical value. They are applicable in various domains, including business analytics, key performance indicators (KPIs), and performance monitoring.
Creating a Metric
From the Visualize tab, click Create Visualization, select the
Metricvisualization format and usewazuh-alerts-*as the index pattern name.On the Metric in Metrics data, set the following values:
Aggregation=MaxField=data.memory_usage_%
Click the Update button.
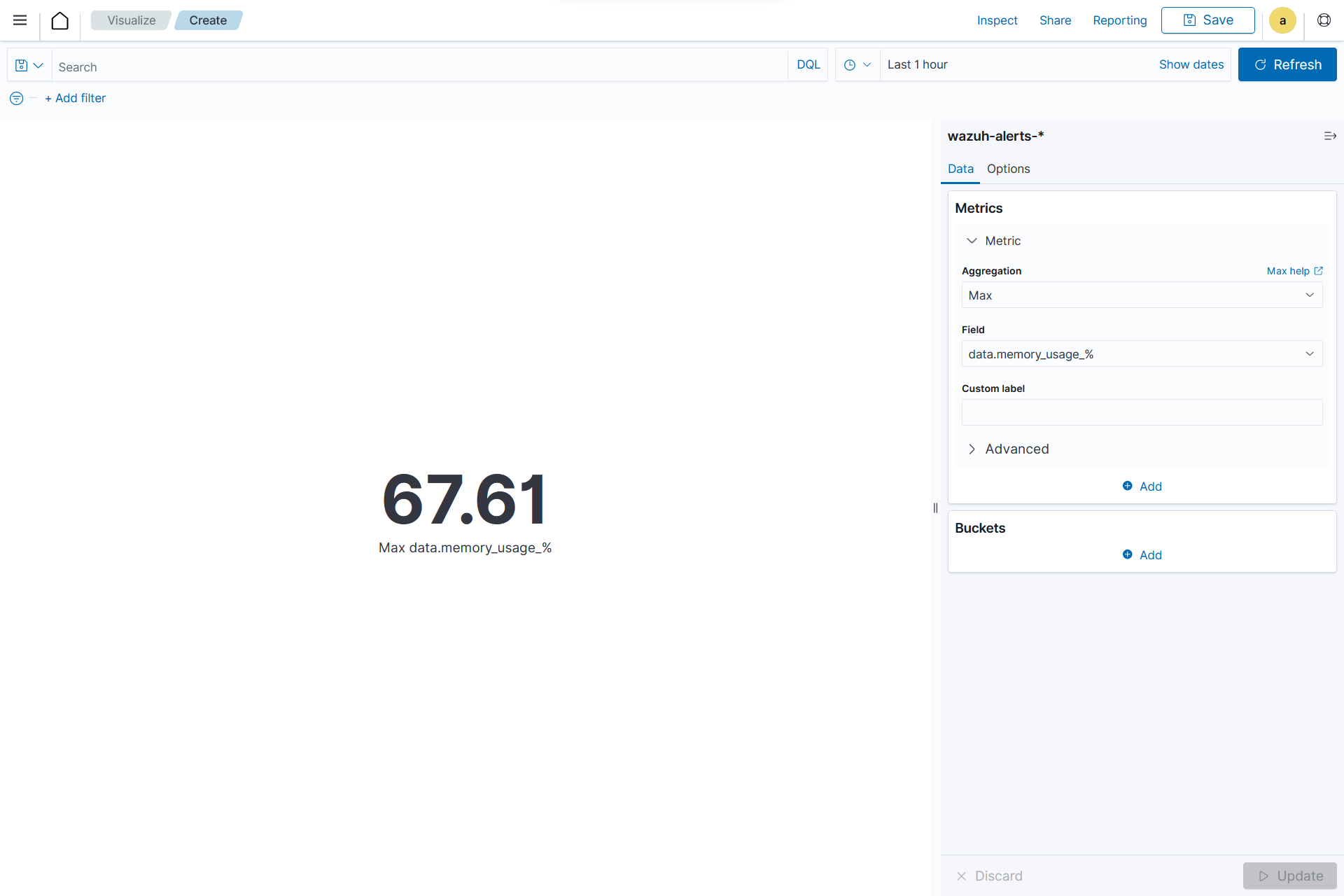
Click the upper-right Save button and assign a title to save the visualization.
Goal
This refers to the desired target that an individual or organization aims to achieve. It represents a specific purpose and serves as a benchmark for measuring progress and achieving a final goal.
Creating a Goal
From the Visualize tab, click Create Visualization, select the
Goalvisualization format and usewazuh-alerts-*as the index pattern name.On the Metric in Data, set the following values:
Aggregation=MaxField=data.sca.passed
Add a
Split groupin Buckets and set the following values:Aggregation=TermsField=data.sca.total_checks
In the
Optionssection, customize theRangesto match the range of existing sca rules.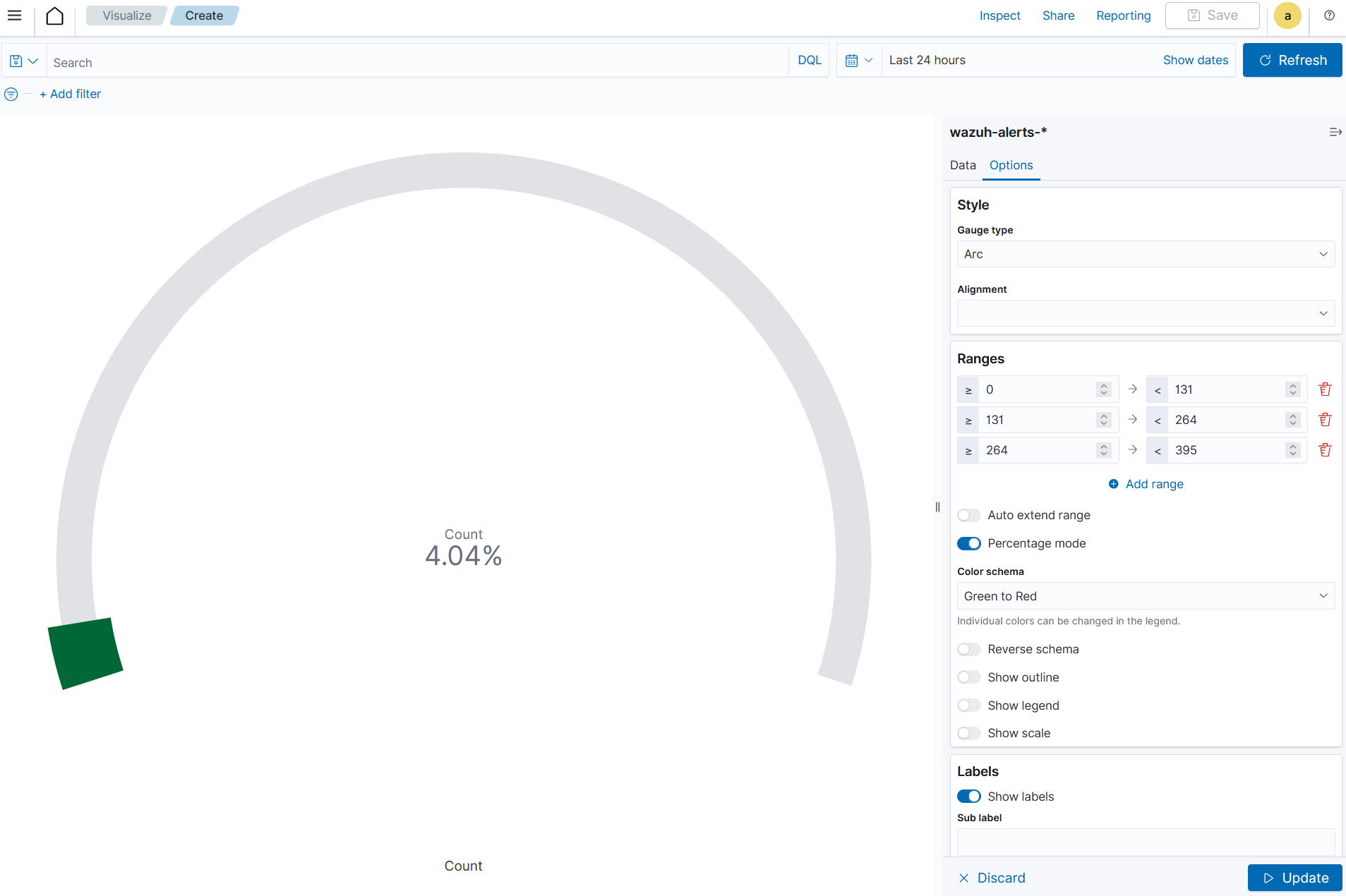
Click the Update button.
Click the upper-right Save button and assign a title to save the visualization.
Gauge
This is a visualization that is represented as a meter. It is commonly used to display a single value within a specific range. The gauge consists of a pointer that shows the current value. This is displayed as a position along a circular or linear scale.
Gauges are used to indicate progress, performance metrics, or levels of achievement. It shows how a metric’s value relates to reference threshold values.
Creating a Gauge
From the Visualize tab, click Create Visualization, select the
Gaugevisualization format and usewazuh-alerts-*as the index pattern name.On the Metric in Metrics data, set the following values:
Aggregation=MaxField=data.disk_usage_%
Click the Update button.
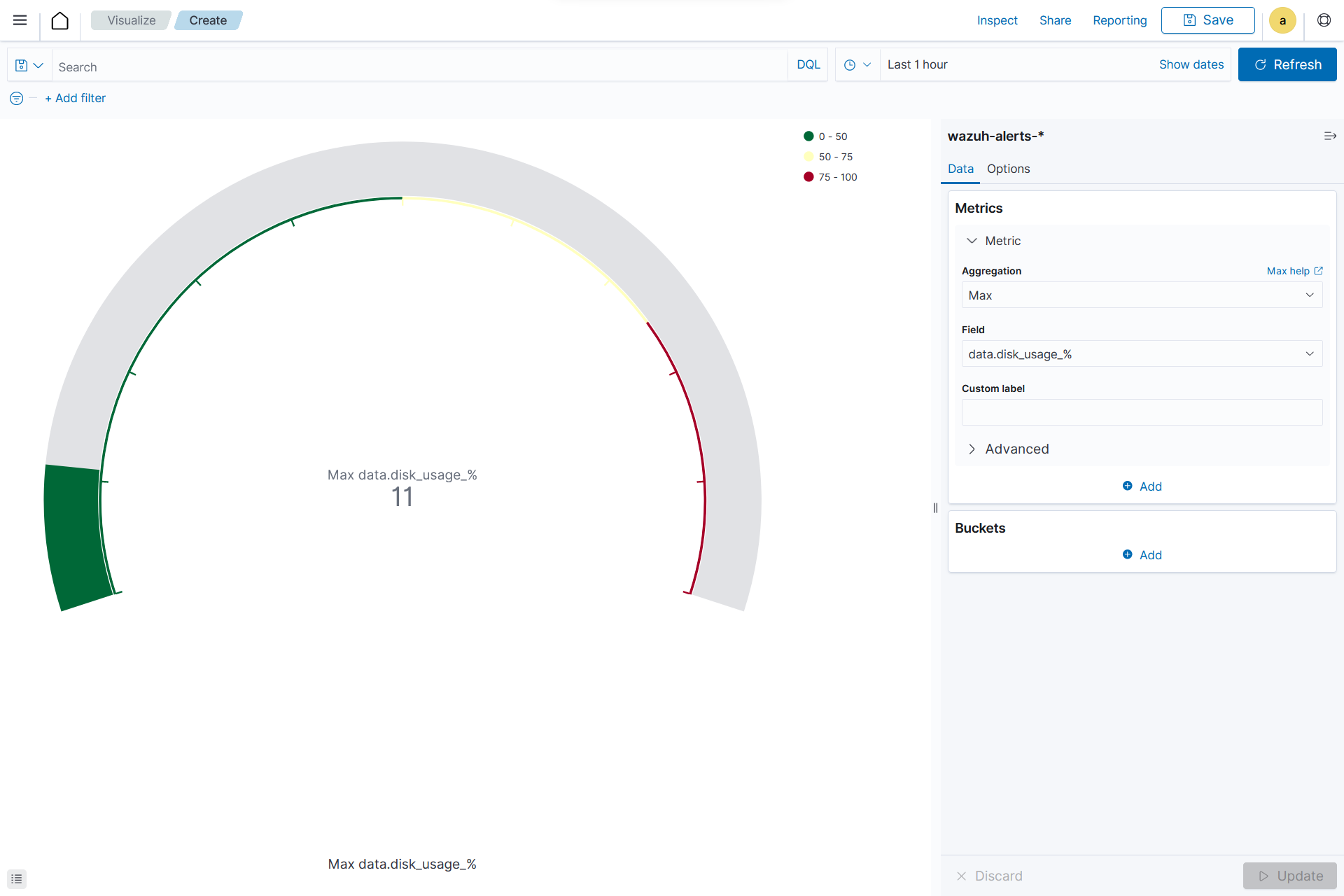
Click the upper-right Save button and assign a title to save the visualization.
Maps
Maps: These are visual representations of geographical regions. Maps display spatial data, such as locations, boundaries, or distributions, on a graphical interface. They provide a means to explore and analyze geographic information, making them valuable for various applications, including navigation, data visualization, and spatial analysis.
Creating a map
From the Visualize tab, click Create Visualization, select the
Mapsvisualization format and usewazuh-alerts-*as the index pattern name.
Click on Add layer.
Select
Documentsas the Data layer.Set the following values in the New layer:
Data source=wazuh-alerts-*Geospatial field=geo.coordinatesNumber of documents=1000
Click the Update button.
Click the upper-right Save button and assign a title to save the visualization.
The following is a list of maps used in visualization:
Coordinate map: This can be used for linking the aggregation of data fields with geographic locations.
Region map: This is a kind of thematic map where we use color intensity to show a metric's value with locations.
Coordinate Map
This uses geographic coordinates to display data points or regions on a map. Coordinate maps allow you to plot and visualize information in relation to specific locations or geographical areas. By using latitude and longitude coordinates, you can represent data in a spatial context.
Coordinate maps are ideal for plotting latitude and longitude coordinates. This allows the visualization of spatial data, such as locations, regions, or density. They are commonly used in geographical analysis, tracking data by location, or displaying demographic information.
Creating a Coordinate map
From the Visualize tab, click Create Visualization, select the
Coordinate Mapvisualization format and usewazuh-alerts-*as the index pattern name.
On the Metric in Data, set the following values:
Aggregation=Count
Add a
Geo coordinatein Buckets and set the following values:Aggregation=GeohashField=OriginLocation
Click the Update button.
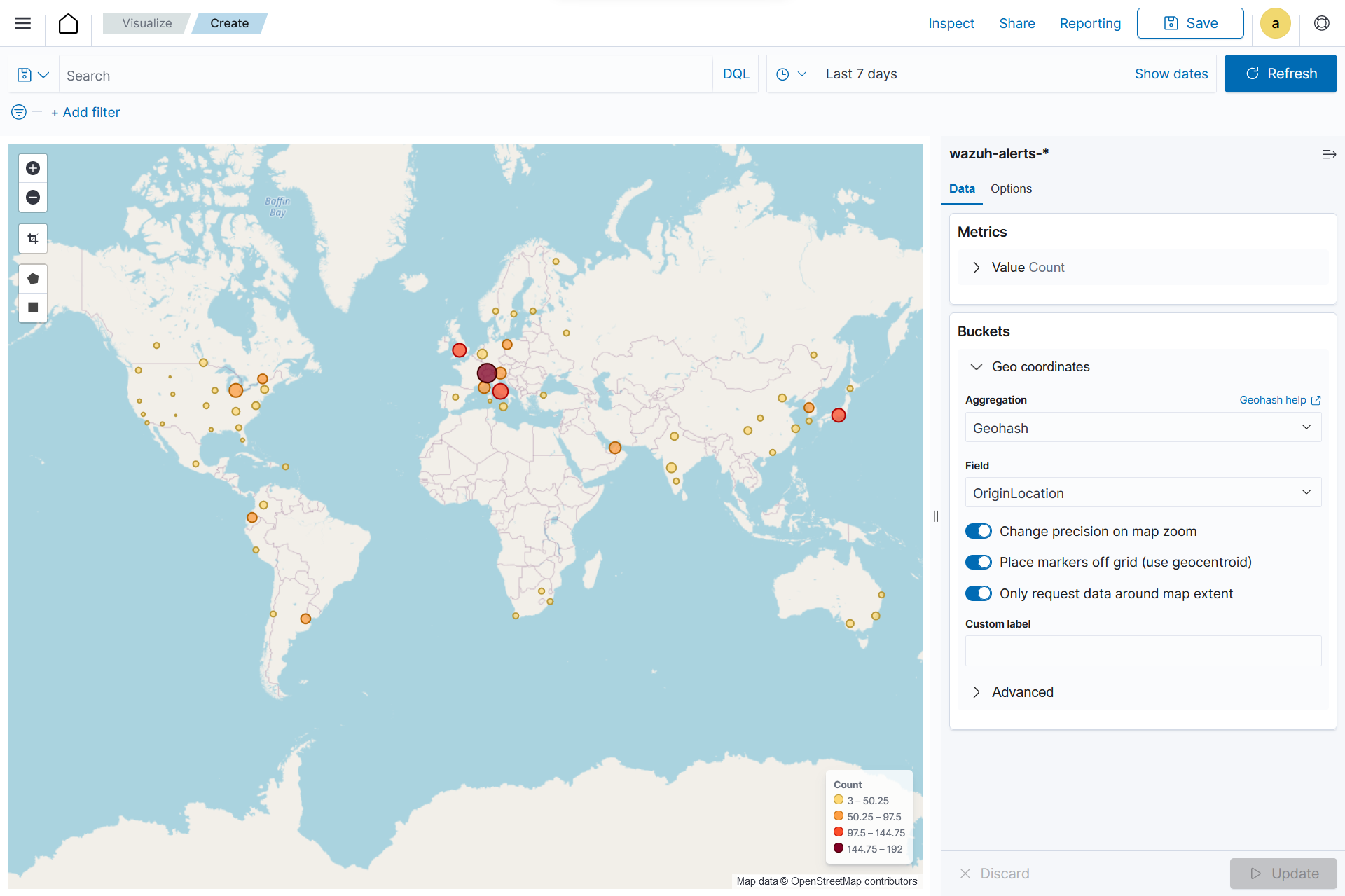
Click the upper-right Save button and assign a title to save the visualization.
Region Map
This is a map-based visualization that displays data by dividing regions into distinct boundaries. Region maps are suitable for displaying data at a territorial level. They are often used in geopolitical analysis, demographic comparisons, or election results.
Create region map
From the Visualize tab, click Create Visualization, select the
Region Mapvisualization format and usewazuh-alerts-*as the index pattern name.
On the Metric in Data, set the following values:
Aggregation=Count
Add a
Shape fieldin Buckets and set the following values:Aggregation=TermsField=DestCountryOrder by=Metric: CountOrder=Descending
Click the Update button.
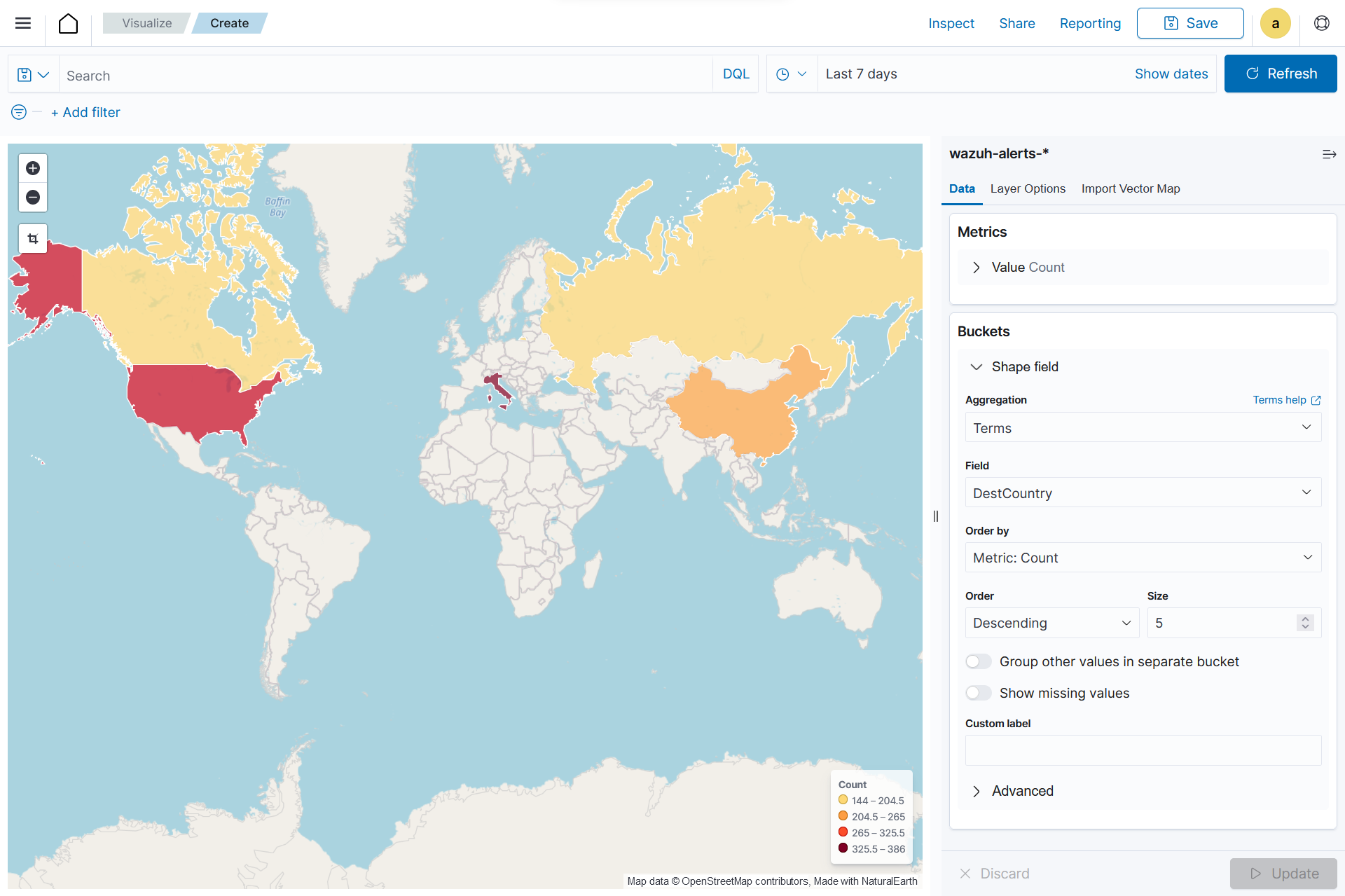
Click the upper-right Save button and assign a title to save the visualization.
Time series
The following is a list of time series used in visualization:
VisBuilder: This is used to display the results from single or multiple indices by combining data from multiple time series datasets.
Time series visual builder: This is used to visualize time series data using data aggregations.
VisBuilder
Visualization Builder is an intuitive tool that allows users to create customized visualizations without programming knowledge. It is beneficial for users who want to quickly generate visual representations of their data without extensive technical knowledge.
As at the time of writing this document, this visualization is experimental. The design and implementation are less mature than stable visualizations and might be subject to change.
Creating a Visualization Builder
From the Visualize tab, click Create Visualization, select the
VisBuildervisualization format and usewazuh-alerts-*as the index pattern name.
Drag a field to the configuration panel to generate a visualization.
On the
Y-axisset aggregation to count.On an
X-axisplace rule.mitre.technique.On the split series place
rule.mitre.tactics.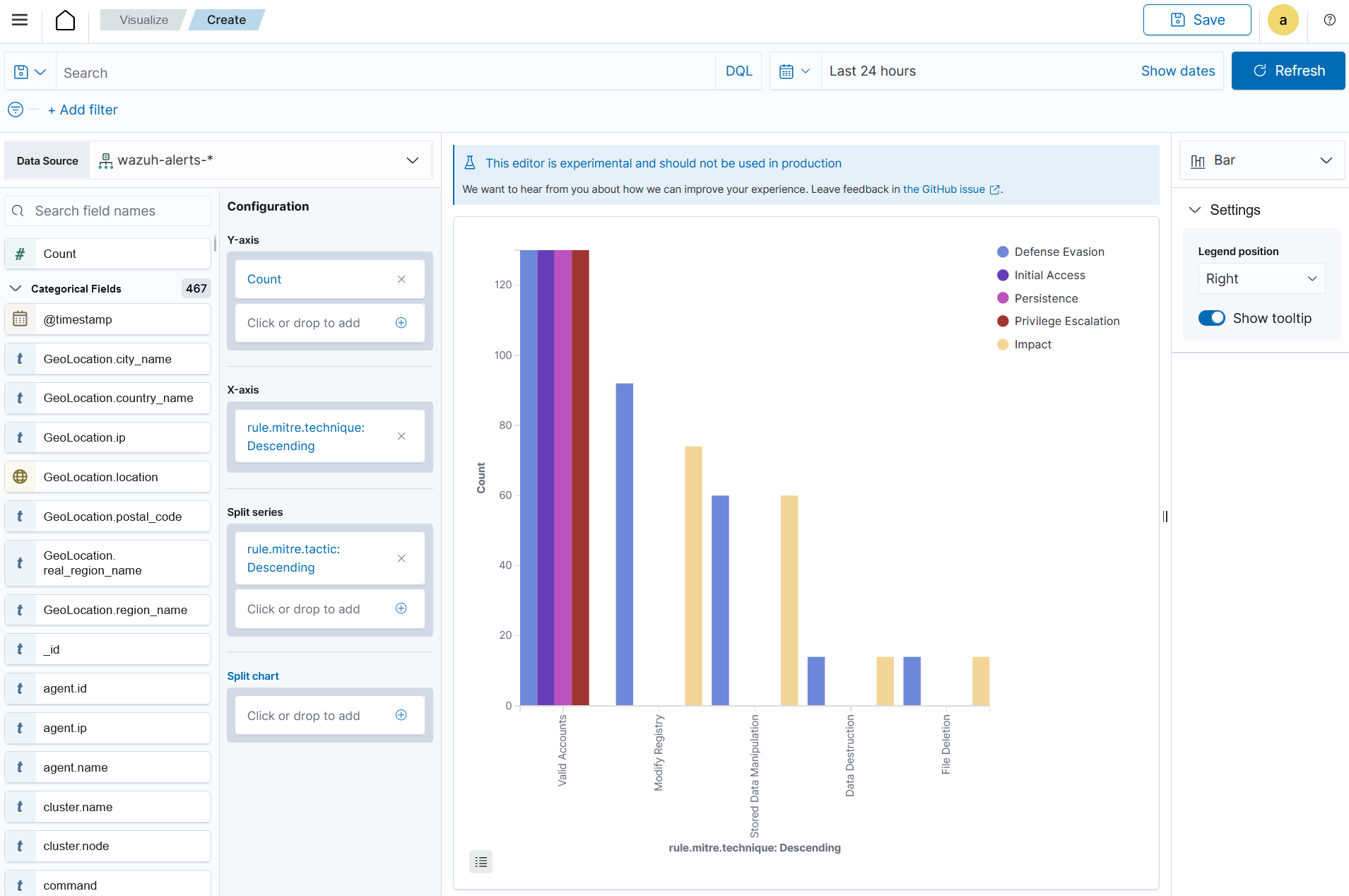
TSVB
Time Series Visual Builder (TSVB) is a component of the Wazuh dashboard that allows users to create visualizations and analyze time series data using a visual pipeline interface. It provides features such as aggregations, filters, and metrics specifically tailored for time-based analysis.
Creating a TSVB
From the Visualize tab, select the
TSVBvisualization format.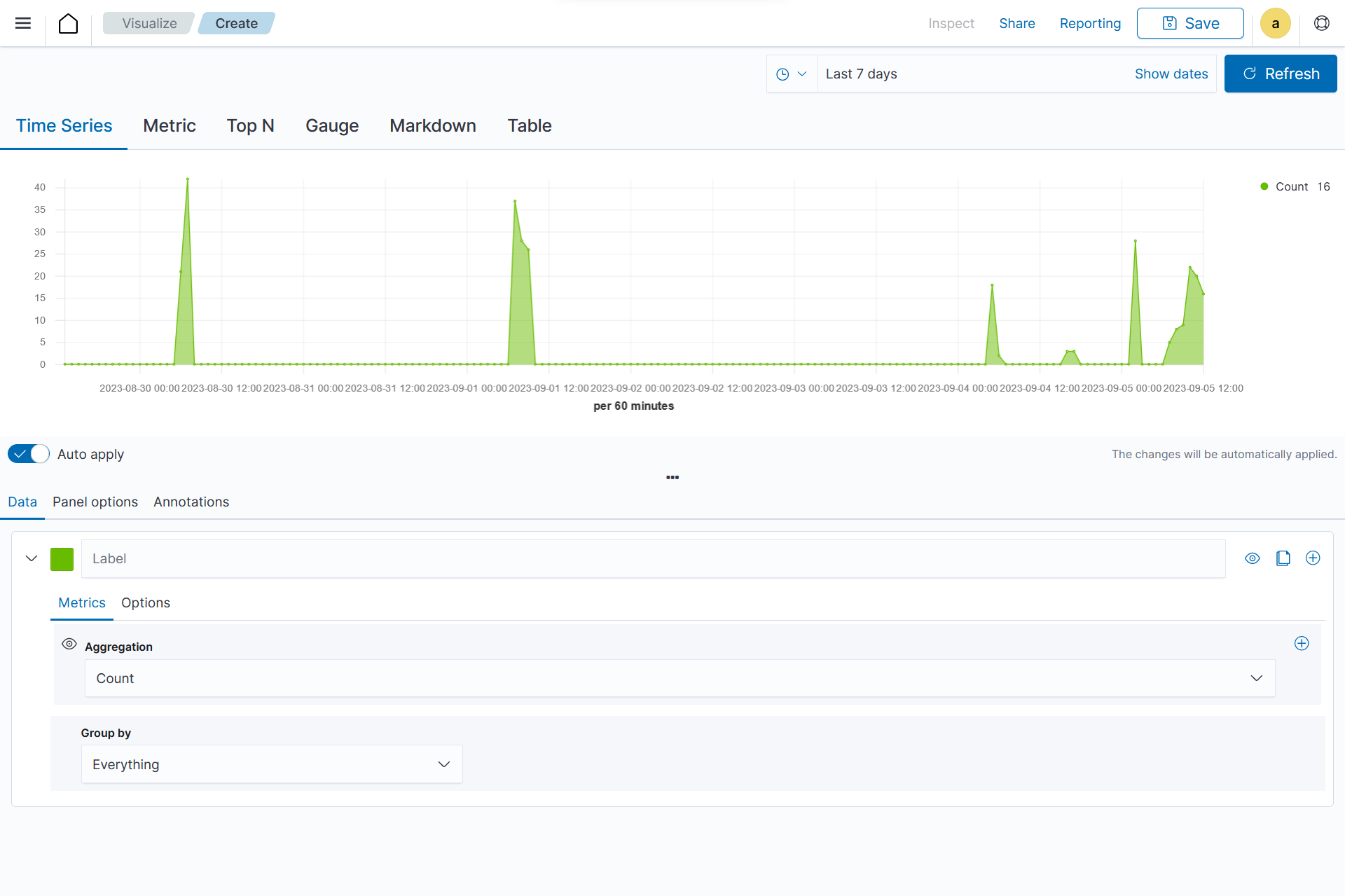
On the Metric in Data, set the following values:
Aggregation=CountGroup by=TermsBy=rule.mitre.tactic
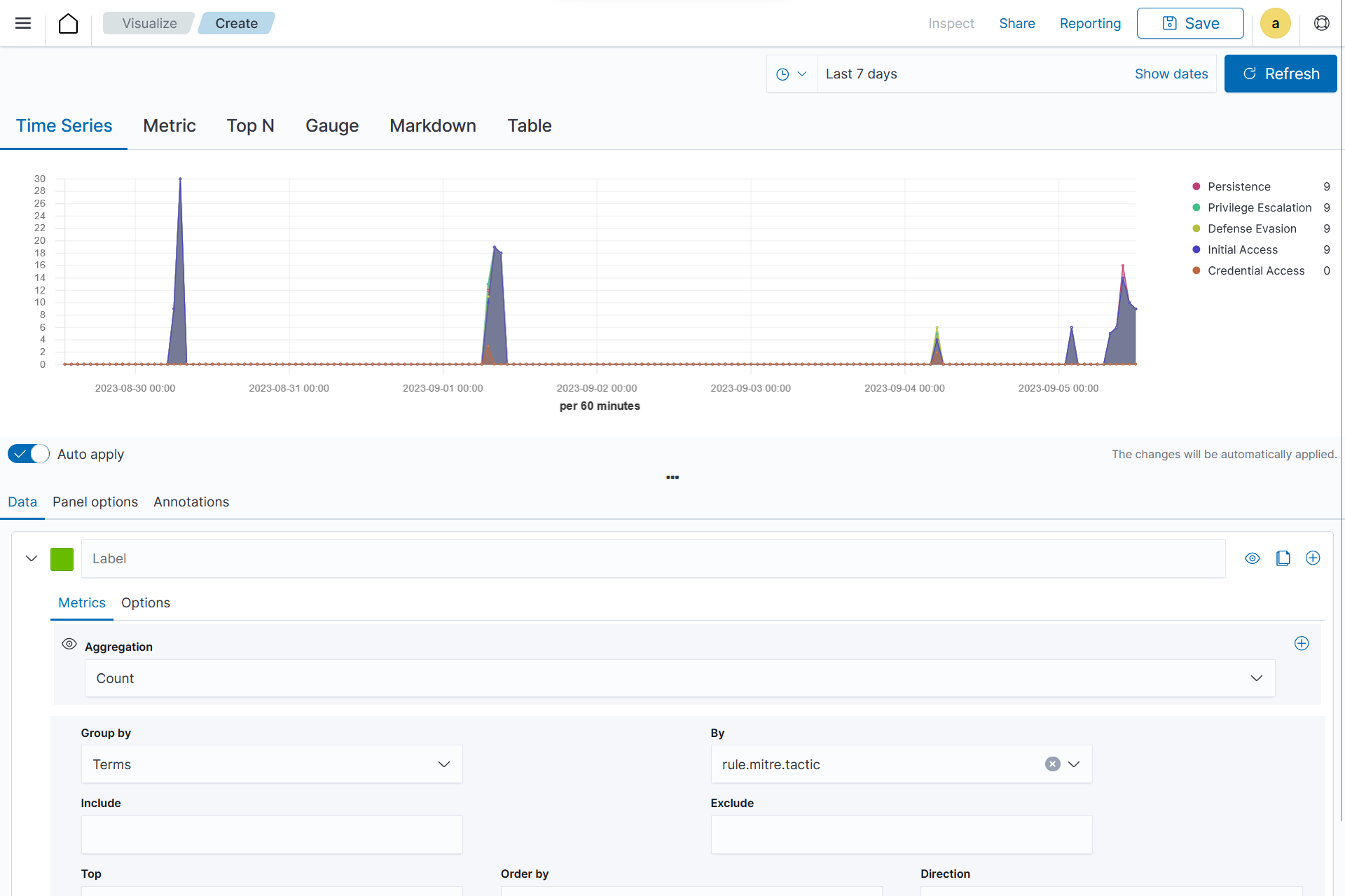
Others
Here are some other items that are used in visualization:
Tag cloud: This is where selected field values are picked for creating a cloud of words.
Markdown: This will display a form for showing information or instructions.
Tag Cloud
This is a visual representation of text data where words are displayed in varying sizes based on their importance. Tag clouds are often used in data visualization, text analysis, or content analysis.
Creating a tag cloud
From the Visualize tab, click Create Visualization, select the
Tag cloudvisualization format and usewazuh-alerts-*as the index pattern name.
On the Metric in Metrics data, set the following value:
Tag size=Count
Add a new Tag in Bucket data and set the following values:
Aggregation=TermsField=rule.mitre.tacticOrder by=Metric: Count
Click the Update button.
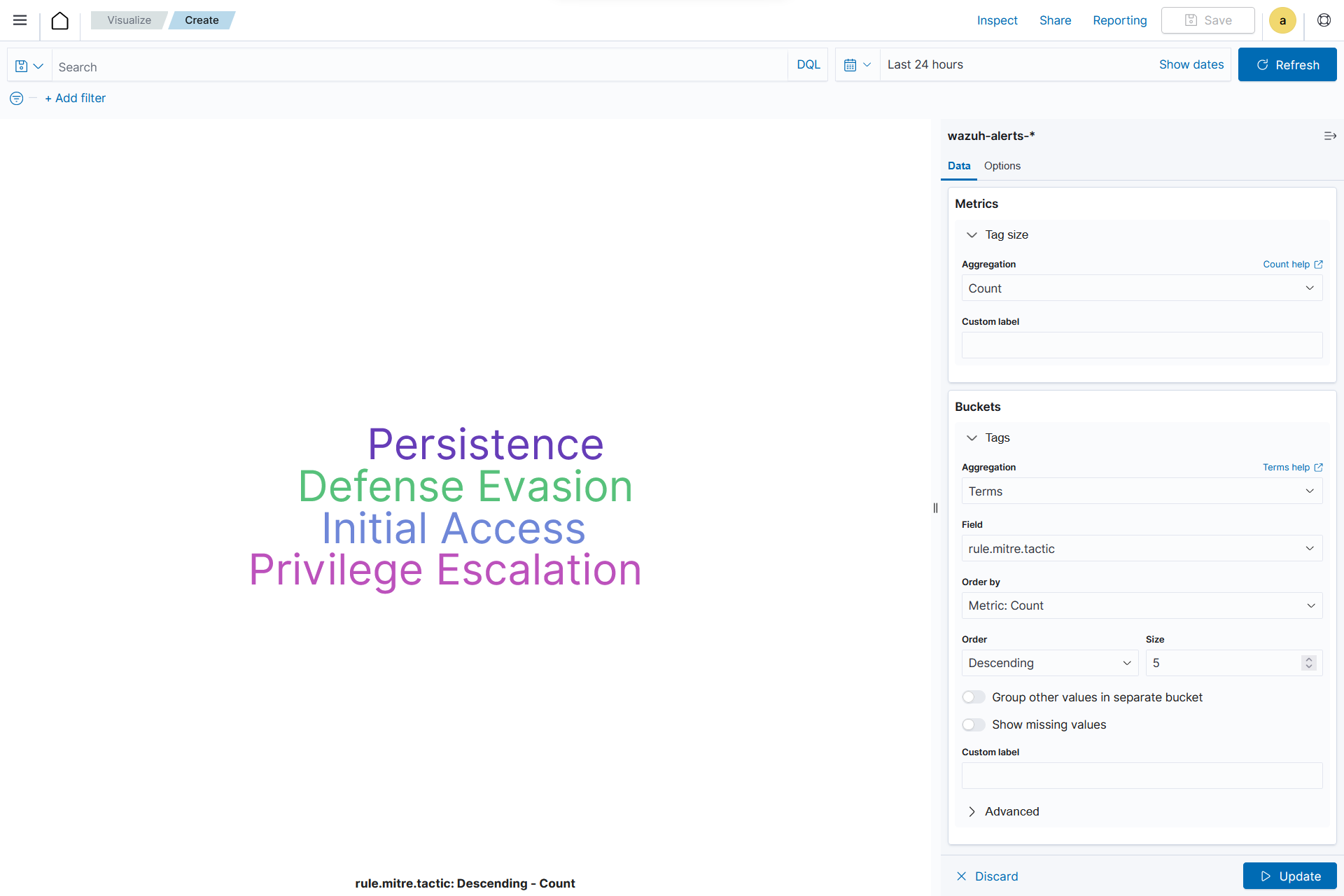
Click the upper-right Save button and assign a title to save the visualization.
Markdown
Markdown is a lightweight markup language that is used for formatting text. It allows users to add structure, emphasis, and styling to plain text documents, without the need for complex coding. Markdown is often utilized in documentation, websites, and note-taking applications to create easily readable and formatted content.
Creating a markdown
From the Visualize tab, click Create Visualization, select the Markdown visualization format and use wazuh-alerts-* as the index pattern name.
After that, we need to do the following:
On the Data tab, add the text content in the given text-area.
On the Options tab, Increase or decrease the font using the controller.
Click on the Update button to show the markdown:
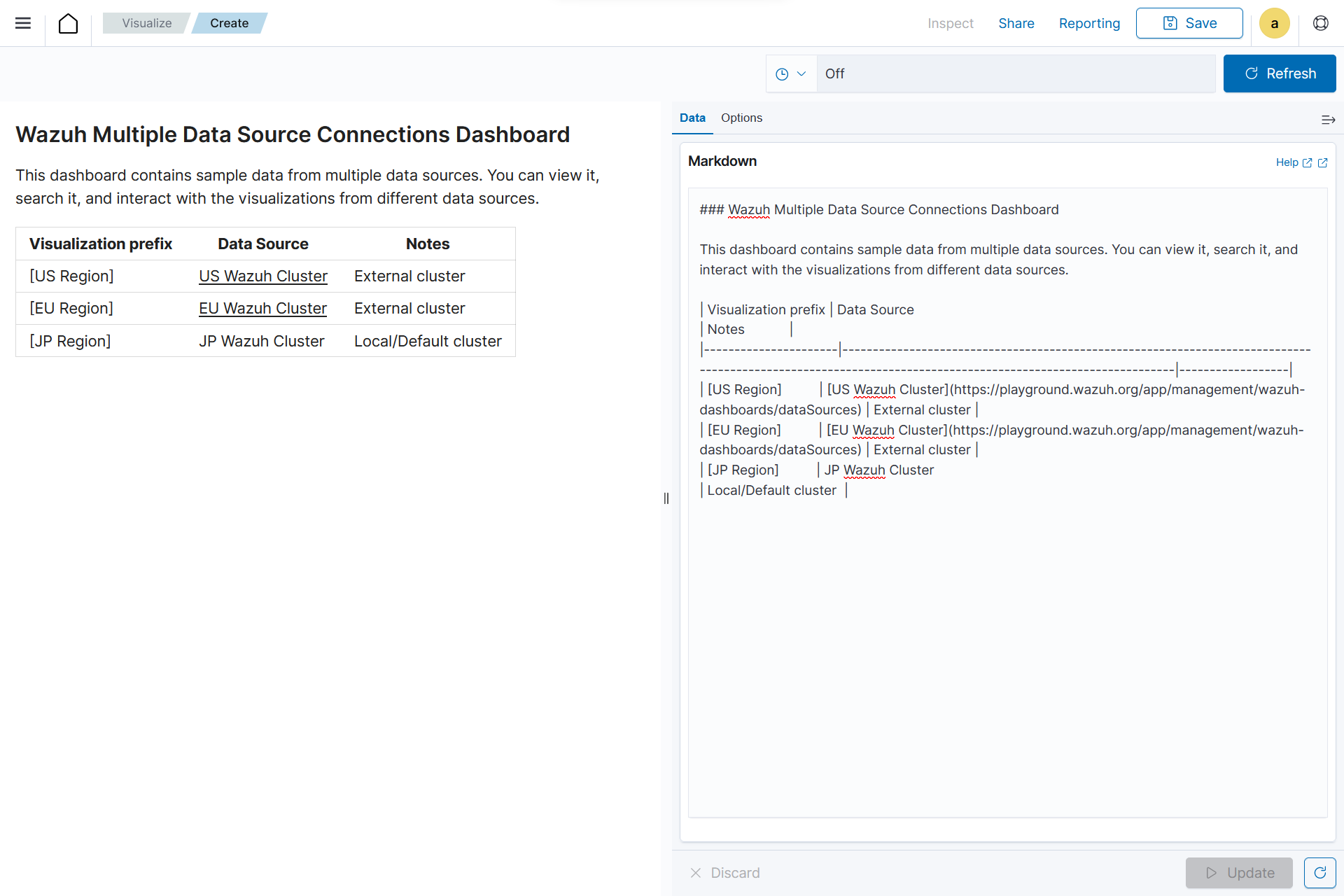
Click the upper-right Save button and assign a title to save the visualization.
Controls
These are interactive tools that provide users with the ability to manipulate or adjust parameters or settings within a software application or user interface. These controls enable users to customize their experience or modify certain aspects of the system according to their preferences. Controls are typically used in interactive applications or interfaces where users need to adjust settings, parameters, or filters to customize their experience or analyze specific aspects of the data.
As at the time of writing this document, this visualization is experimental. The design and implementation are less mature than stable visualizations and might be subject to change.
Creating controls
From the Visualize tab, click Create Visualization, select the
Controlsvisualization format.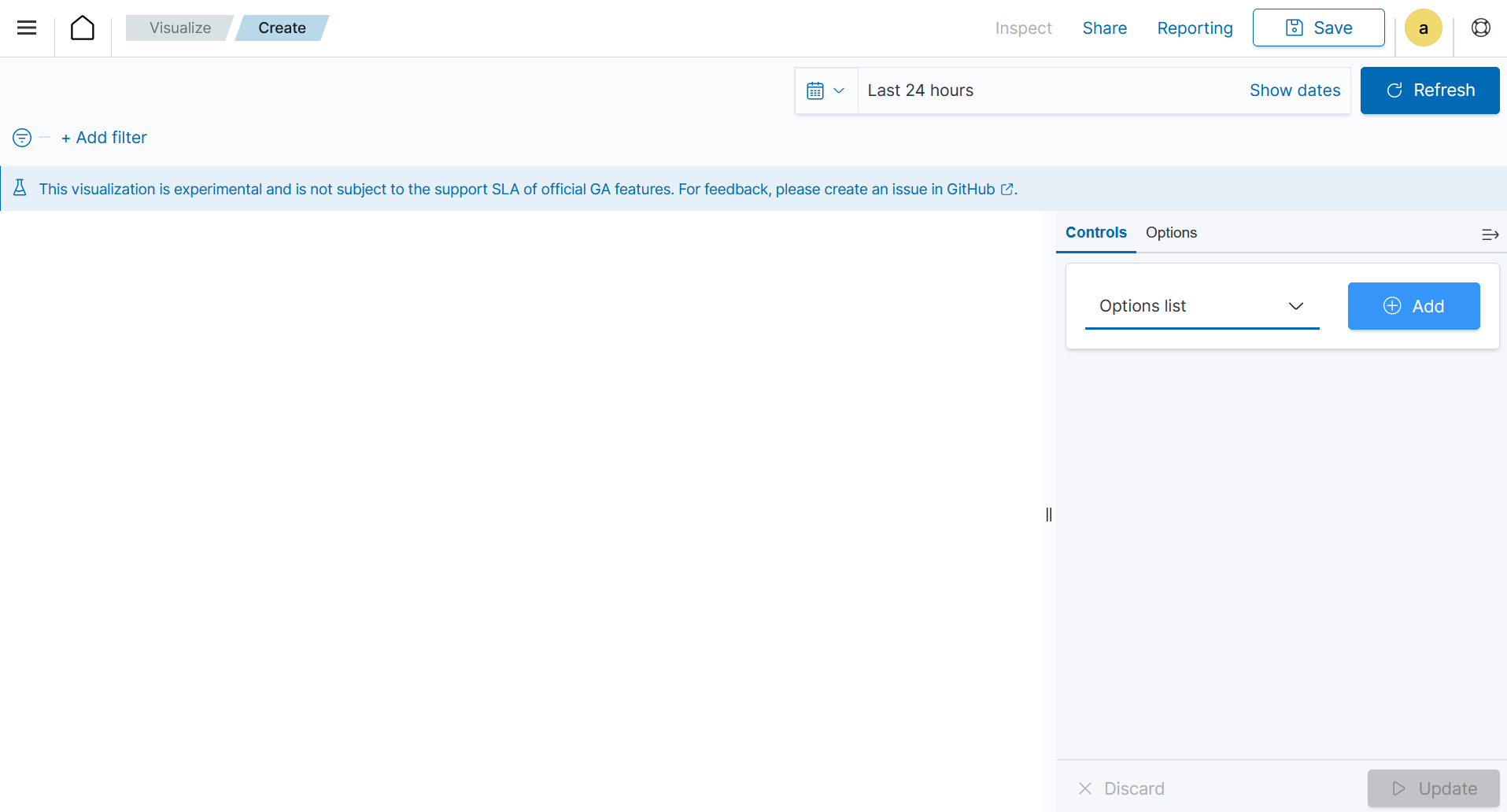
Add a new
Options listand set the control Label as Mitre tactic.Choose a source for the chart. Here we selected
wazuh-alerts-*as the index to use.Select the field
rule.mitre.tactic.Add a new
Range sliderand set the control Label as Quantity.Select
wazuh-alerts-*as the index to use.Select the field
rule.level.Click the Update button.
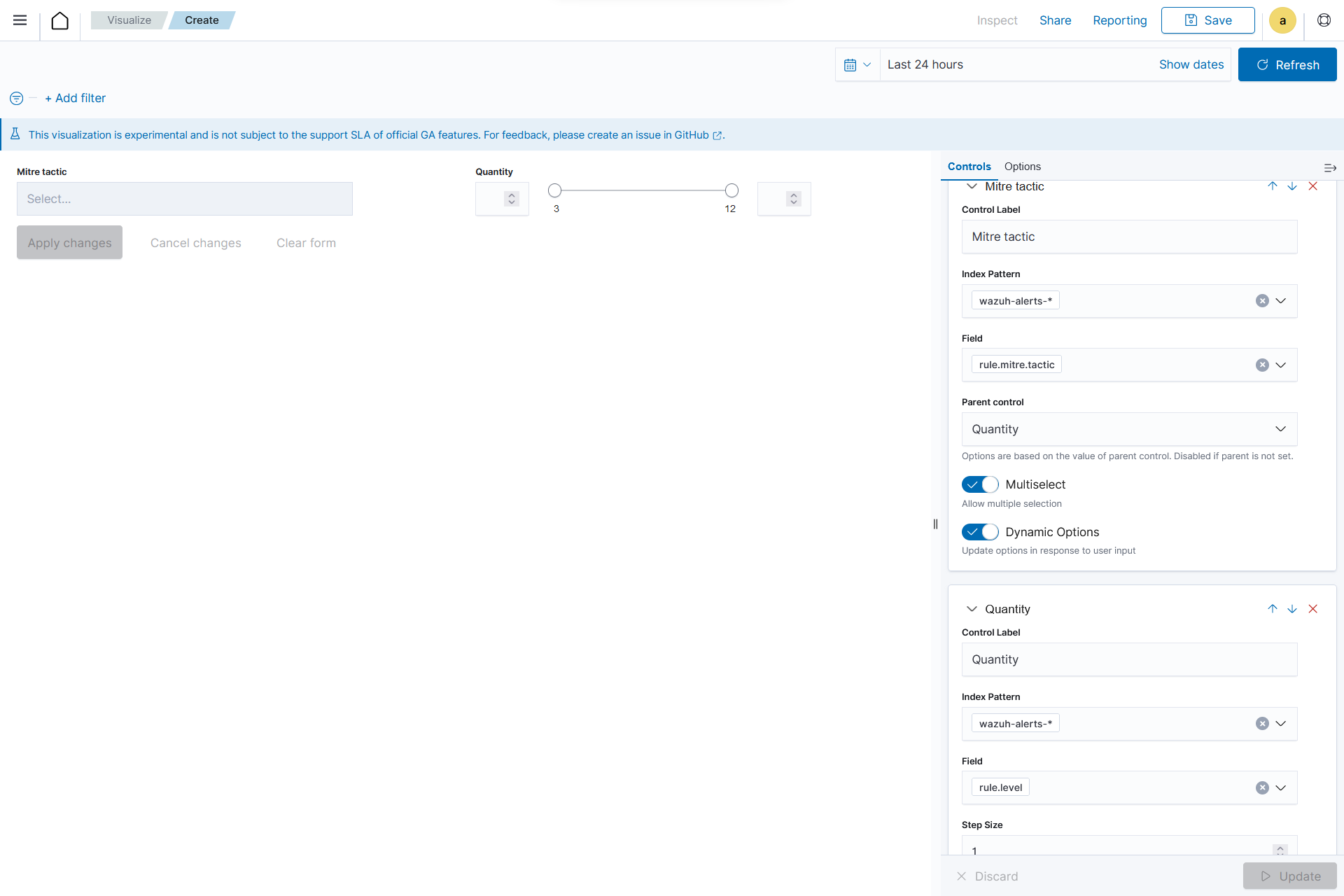
Click the upper-right Save button and assign a title to save the visualization.
Gantt Chart
This is a visualization that is used to illustrate project schedules or timelines. It displays a horizontal bar for each task or activity, representing its start and end dates. The length of the bars indicates the duration of each task, and they are arranged along a timeline to demonstrate the order and duration of various project activities.
Gantt charts are valuable for project management or scheduling tasks over time. They help in visualizing project timelines, dependencies, and resource allocation.
Creating a Gantt chart
From the Visualize tab, click Create Visualization, select the
Gantt Chartvisualization format and usewazuh-alerts-*as the index pattern name.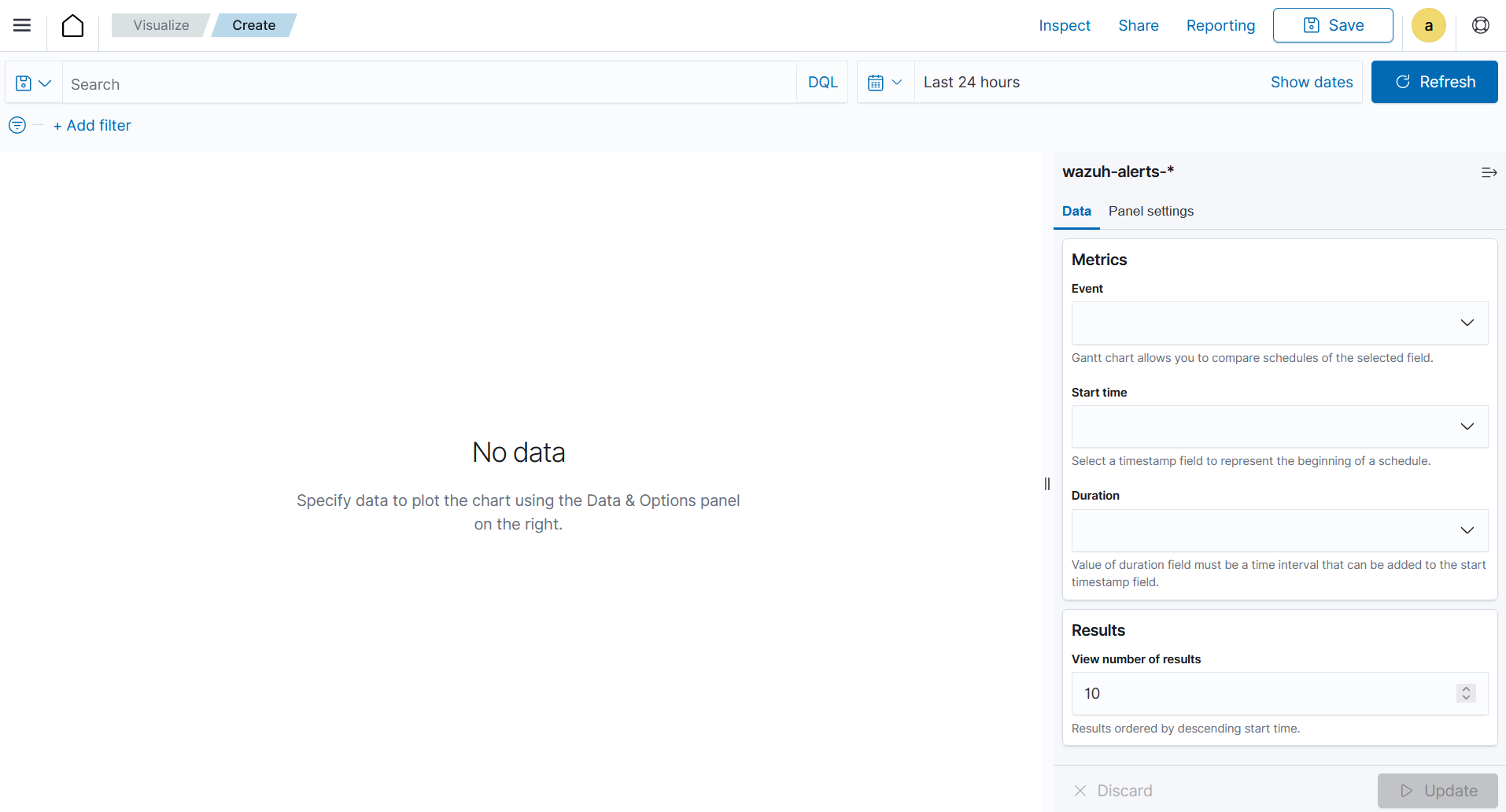
Choose a source for the chart. Here we selected
wazuh-alerts-*as the index to use.On the Metric in Metrics data, under Event, select a log data.
On the Start time field for the Event, select a
timestampfield for the start of a schedule. This is the timestamp used for the beginning of the selected Event.On the Duration field for the Event, select a time interval field for the Event duration. This is the amount of time that is added to the start time.
On the Results field, select the number of events that will be shown on the chart. The events will be sequenced based on the Start time, from the earliest to the latest.
To adjust the colors, axis labels and time format, navigate to the Panel settings.
Click the Update button.
Click the upper-right Save button and assign a title to save the visualization.
Hover over a bar to see the duration of that event.
Timeline
This is a chronological display of events or activities, often depicted as a horizontal line with dates or time periods marked along it. Timeline builds time-series using functional expressions.
They are commonly used in historical analysis, project planning, or storytelling.
Creating Timeline
From the Visualize tab, click Create Visualization, select the
Timelinevisualization format.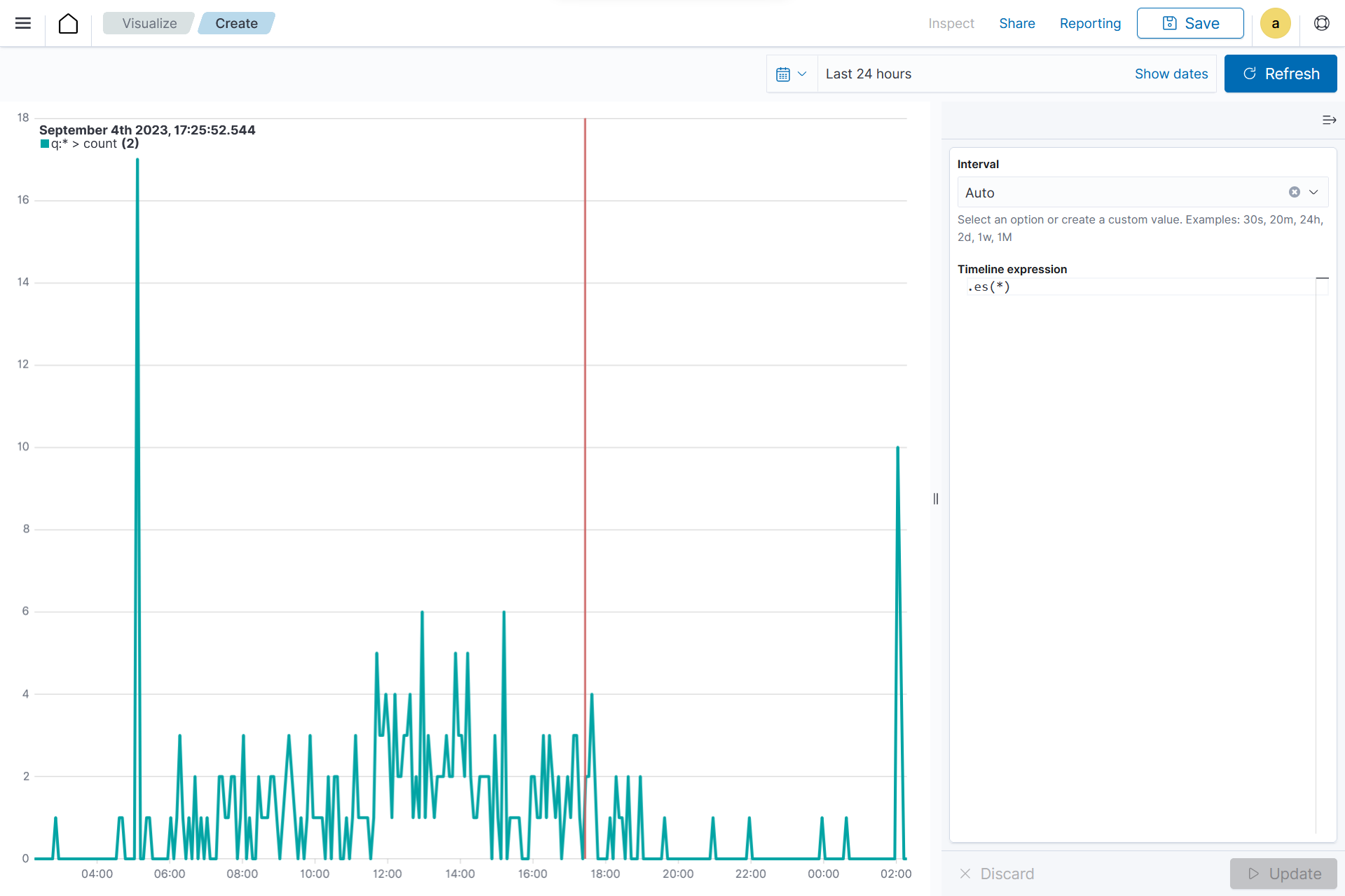
Choose a source for the chart. In the Timeline expression windows, within
.es(*). The expression.es(*)is a wildcard value that represents all the indexes currently within the Wazuh indexer, combined together. Here we selectedwazuh-alerts-*as the index to use..es(index=wazuh-alerts-*)
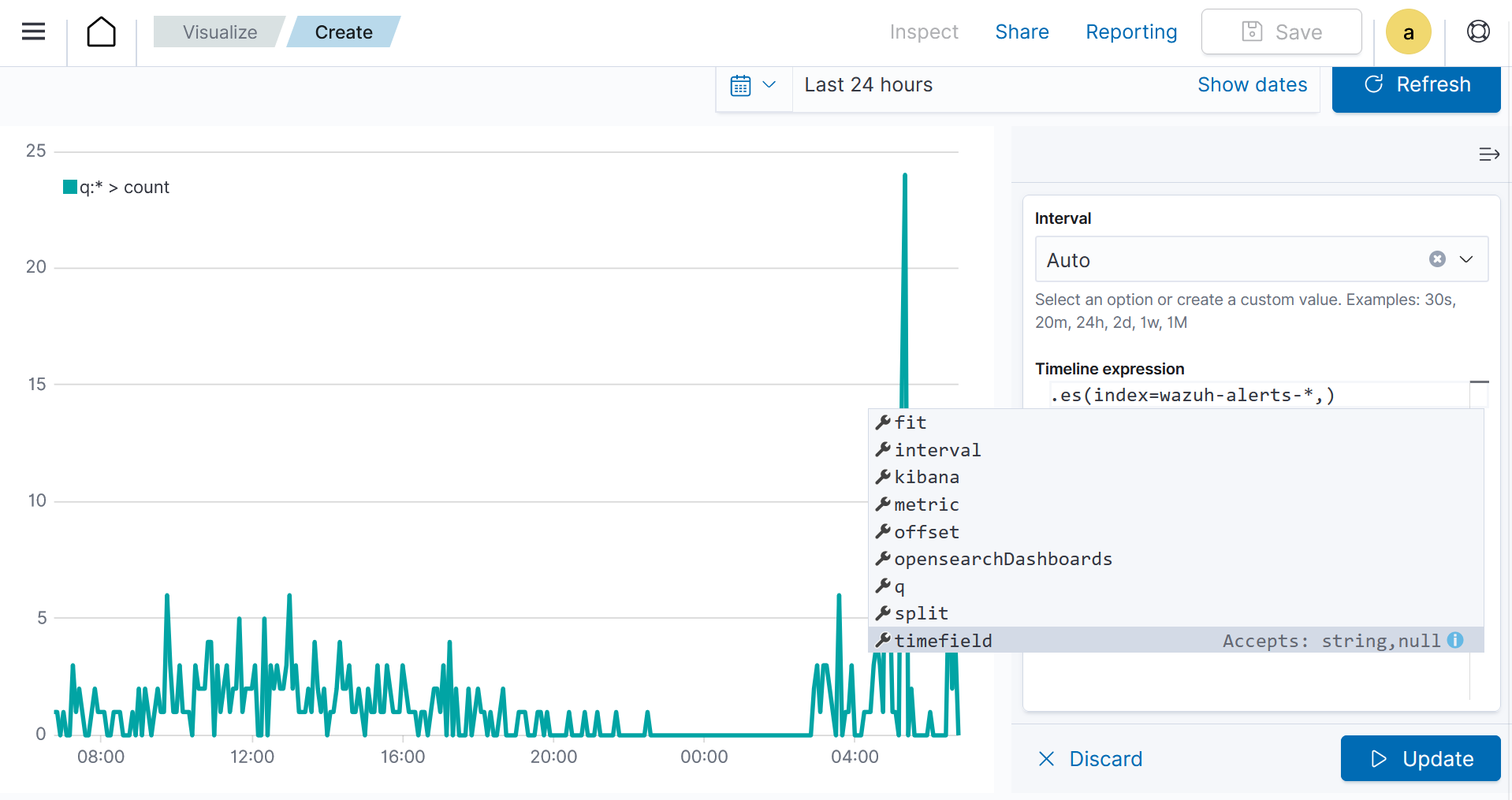
Where:
Index represents the data storage unit containing the data to be used for visualization.
Interval represents the time duration between data points or events.
Timefield represents a specific field in a dataset that holds timestamp or time information for each data point.
Metric represents the quantitative measure to be used from the data.
Offset is used to adjust the time displayed on the timeline for aligning with specific events.
opensearchDashboards represents a platform that provides a web-based interface for visualizing and exploring real-time data.
Q represents a query or set of queries used to filter and retrieve specific data for display.
Split represents the function that divides or groups data into segments based on a specified parameter for visualization and analysis.
A sample query:
.es(index=wazuh-alerts-*, timefield=@timestamp, metric=count:request).aggregate(function=avg)
Vega
This is a versatile declarative language for creating interactive visualizations. It allows users to define visualizations using JSON syntax. It allows users to define complex visualizations using JSON syntax and is suitable for advanced data visualization needs.
Creating dashboards
Dashboards transform your data from one or more single visualization perspectives into a group of visualizations that provide a clear representation of your data. This allows you to concentrate solely on the data that matters to you by presenting a dynamic representation for your data.
To create a custom dashboard, do the following:
Click on the upper-left menu icon and navigate to OpenSearch Dashboards > Dashboard > Create new dashboard.
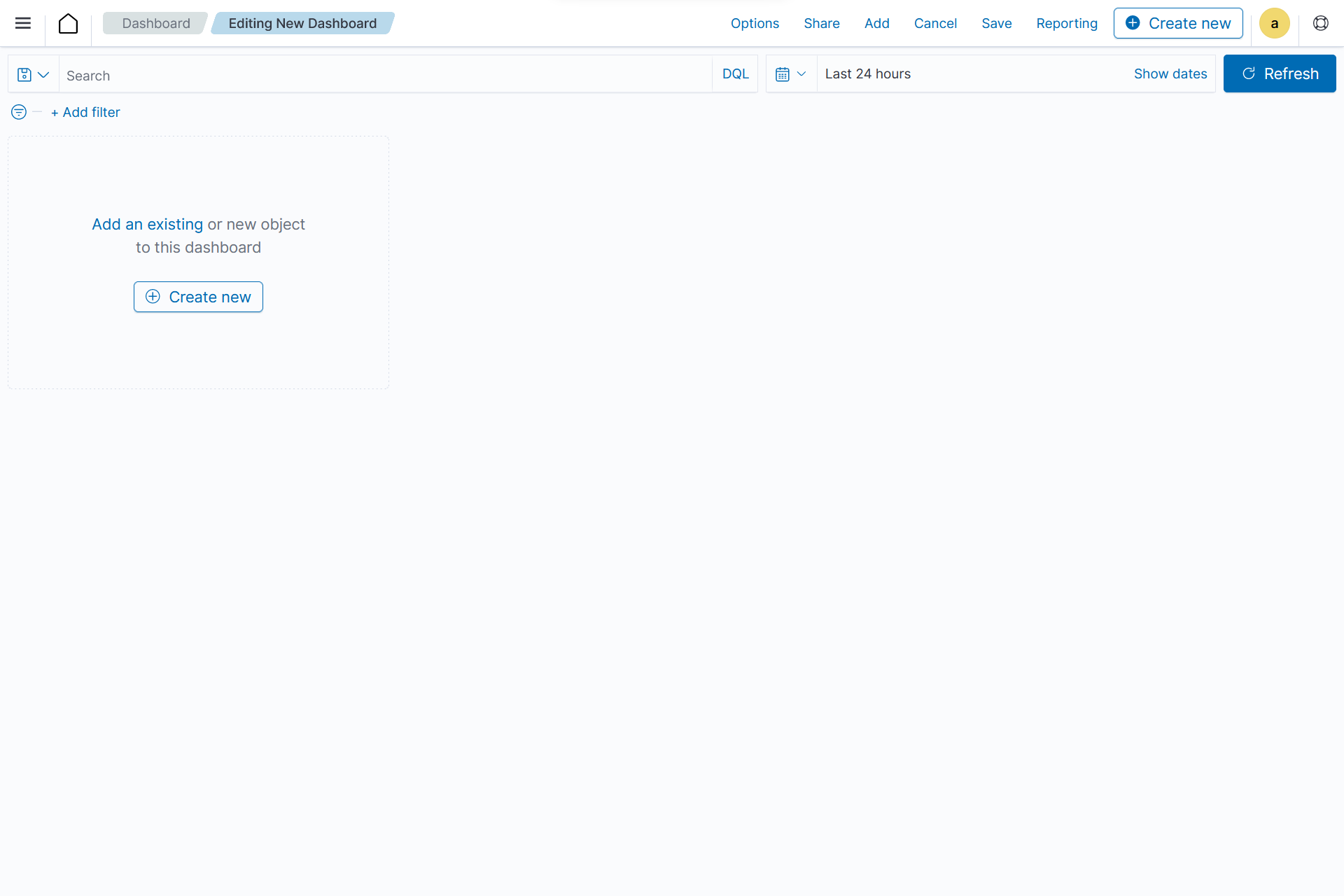
Click Add an existing and select the newly created visualizations to populate the dashboard.
Save the dashboard by selecting the Save option on the top-right navigation bar.