Wazuh server cluster
Introduction
We recommend reading: Wazuh server cluster.
In high-demand environments, Wazuh agents are enrolled at scale and at a rapid pace. A single Wazuh server node has limited capacity to process such large volumes of events, making workload distribution necessary. Therefore, horizontal scaling becomes the proper approach to balance the workload for a large number of agents.
The Wazuh server processes security events received from Wazuh agents and generates alerts. To ensure accurate event handling, all information required to receive and manage agent data must remain synchronized across Wazuh server nodes. This information includes:
Agent keys: This allows Wazuh server nodes to accept incoming connections from the Wazuh agents.
Agent shared configuration: This allows the Wazuh server nodes to send the Wazuh agents their configuration.
Agent group assignment: This allows every Wazuh server node to know which configuration to send to the Wazuh agents.
Custom decoders, rules and CDB lists: This allows the Wazuh server nodes to correctly process events from the Wazuh agents.
Agent last keep alive and OS information: This is received once a Wazuh agent connects to a Wazuh server node. This helps to know whether the Wazuh agent is reporting or not.
With this information synchronized, any node in the Wazuh server cluster can process data and generate alerts from connected Wazuh agents. This synchronization enables horizontal scaling, allowing the Wazuh environment to expand seamlessly as new agents are added.
Architecture overview
The following diagram shows a typical Wazuh server cluster architecture:
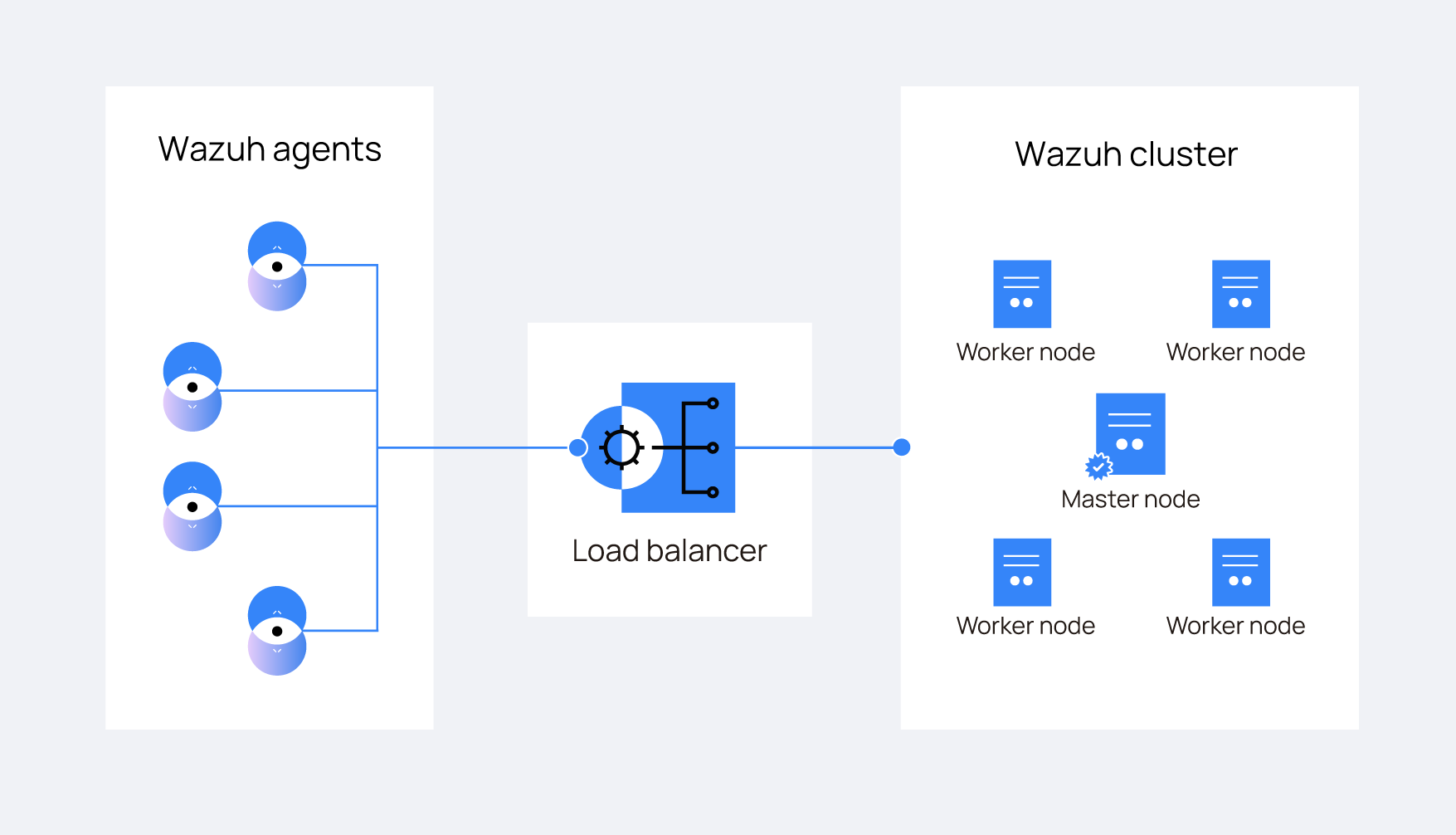
Wazuh agents are configured to report to a load balancer, which distributes network traffic across all Wazuh server nodes in the cluster. This approach allows new server nodes to be added without modifying the agent configuration, as all agents communicate through a single load balancer IP address.
Note
The Wazuh server cluster doesn't manage the load balancer.
Types of nodes
There are two types of Wazuh server cluster nodes. The node types define the tasks performed by the node within the cluster, and also defines a hierarchy of nodes used to know which information prevails when doing synchronizations.
Master
The master node is responsible for:
Receiving and managing agent registration requests.
Creating shared configuration groups.
Updating custom rules, decoders and CDB lists.
Synchronizing all this information to the workers nodes.
All the outlined responsibilities of the master node listed above is called Integrity. It is synchronized from the master to the workers even if the workers have a more recent modification time or a higher size.
Master nodes can also receive and process events from agents the same way a worker would do.
Worker
A worker node is responsible for:
Redirecting agent registration requests to the master node.
Receiving updates from the master node.
Receiving and processing events from agents.
Sending last keep alive messages from agents and remoted group assignments to the master node.
If any integrity file is modified in a worker node, its content will be replaced with the version on the master node.
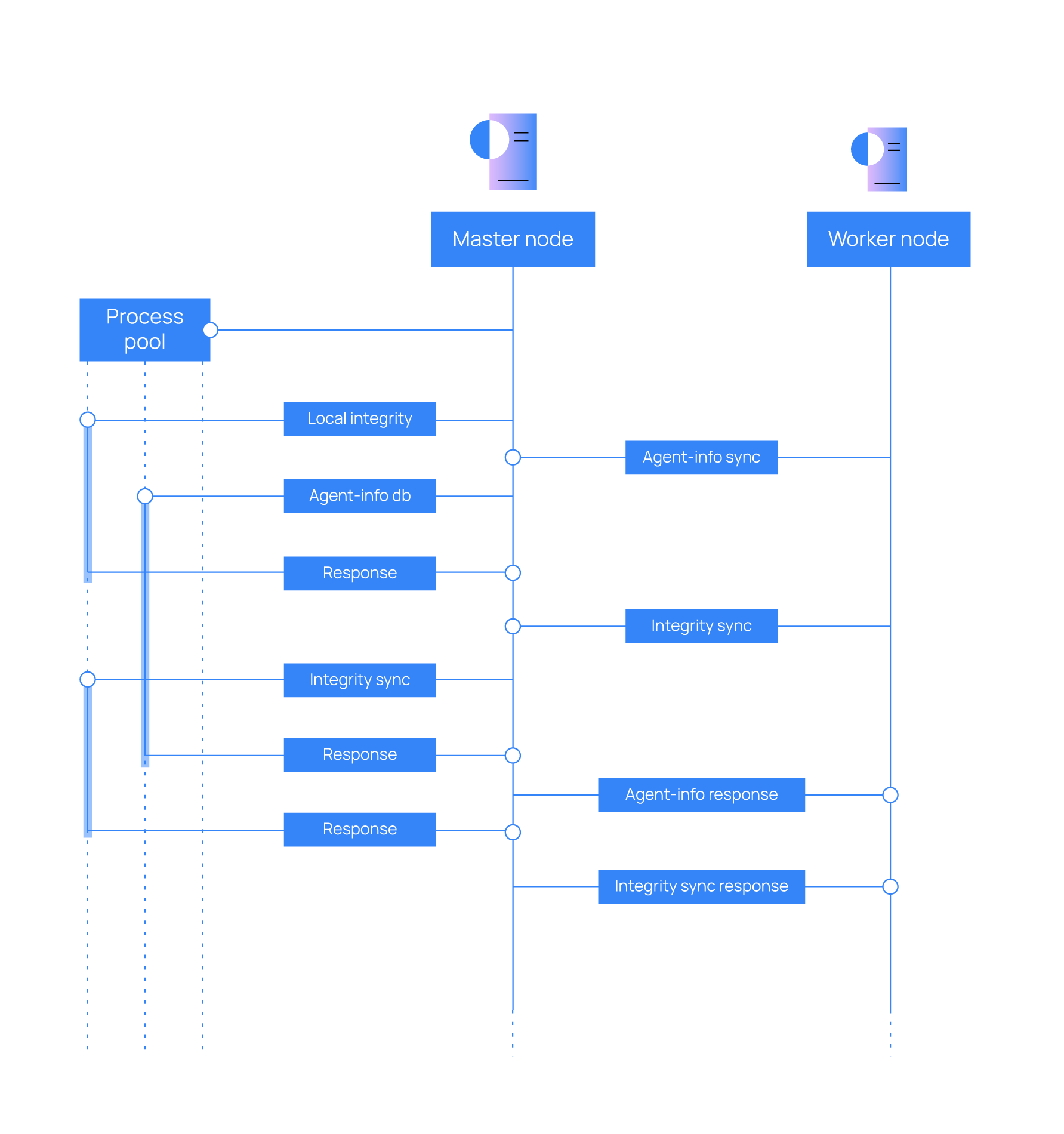
Workflow
The image below shows a schema of how a master node and a worker node interact with each other in the synchronization process. Every dotted square represents a synchronization task and they all work in parallel:
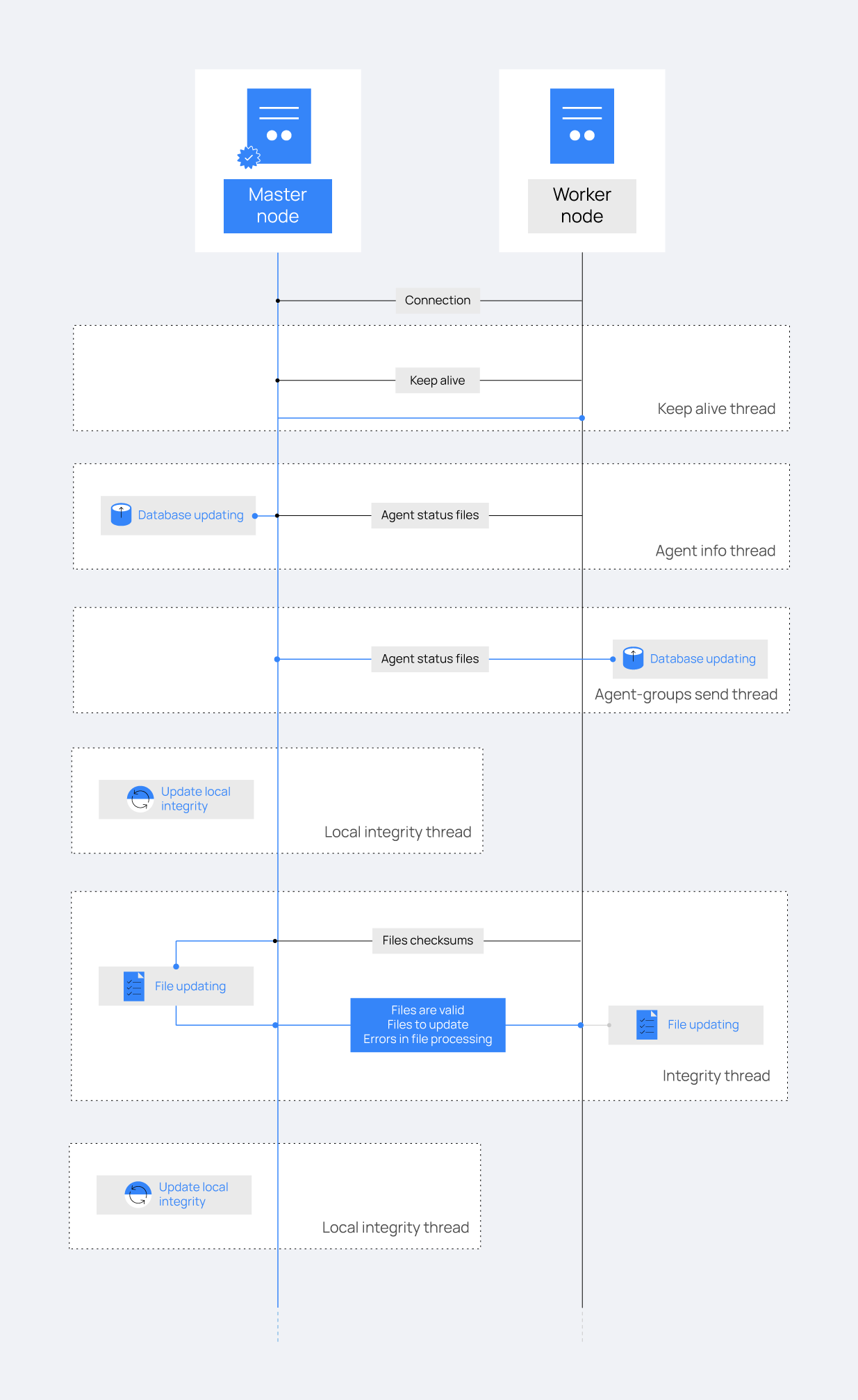
Threads
The following tasks can be found in the cluster, depending on the type of node they are running on:
Thread name |
Node |
|---|---|
Keep alive - Send to master |
Worker |
Integrity sync |
|
Agent info sync |
|
Keep alive - Check workers |
Master |
Agent groups send |
|
Local agent-groups |
|
Local integrity |
|
Sendsync |
|
Distributed API |
Both |
Keep alive thread
Worker nodes in the Wazuh server cluster periodically send keep-alive messages to the master node. The master node records the timestamp of the last keep-alive received and monitors the expected interval for each worker. If a worker node fails to send a keep-alive within the defined time limit, the master marks it as disconnected and closes the connection. Once the worker node detects the disconnection, it automatically attempts to reconnect to the master node.
This mechanism helps maintain cluster stability by automatically removing nodes that are unreachable or experiencing network issues.
Integrity thread
The integrity thread is responsible for synchronizing integrity data between the Wazuh server master node and all worker nodes. The synchronization process is initiated by the worker node and occurs in the following stages:
The worker node requests permission from the master node to start the synchronization process. Permission is granted only after any ongoing synchronization process has completed. This prevents overlap between concurrent synchronization operations. Synchronization processes that take too long are considered locked due to errors. When a process is marked as locked, new integrity synchronization requests can be approved.
By default, the maximum time allowed for a synchronization process is 1000 seconds. This value can be modified with the
max_locked_integrity_timevariable in the cluster.json file.The worker node sends the master node a JSON file containing the following information:
Path
Modification time
Blake2b checksum
Information showing whether the file is a merged file or not. If it is a merged file, it shows the following information:
The merge type
The filename
The master node compares the received checksums with its own and creates three different file groups:
Missing: Files that are present in the master node but are missing in the worker node. They must be created in the worker.
Extra: Files that are present in the worker node but missing in the master. They must be removed from the worker node.
Shared: Files that are present in both master and worker but have a different checksum. They must be updated on the worker node with the version from the master node.
The master node then creates a ZIP package containing a JSON file with the required integrity information and any files the worker node needs to update. The maximum size of this package is defined by the
max_zip_sizevariable in the cluster.json file. If the package exceeds this limit, the remaining files are synchronized during the next integrity synchronization cycle.Once the worker node receives the package, it updates the necessary files. If there is no data to synchronize or there has been an error reading data from the worker, the worker is always notified about it. Also, if a timeout error occurs while the worker node is waiting to receive the zip, the master node will cancel the current task and reduce the zip size limit. The limit will gradually increase again if no new timeout errors occur.
Agent info thread
The agent info thread synchronizes the last keep-alive messages and operating system information from worker nodes with the Wazuh server master node. The synchronization process is initiated by the worker node and occurs in the following stages:
The worker node requests permission from the master node before starting synchronization. This prevents multiple synchronization processes from running at the same time.
The worker node queries the local wazuh-db service to retrieve information about agents marked as not synchronized.
The worker node sends the master node a JSON string containing the information retrieved from wazuh-db.
The master node sends the received information to its local wazuh-db service, where it is updated.
Note
If there is an error during the update process of one of the chunks in the database of the master node, the worker node is notified.
Agent groups send thread
The agent groups send thread synchronizes Wazuh agent group assignments (agent-groups) from the master node to all worker nodes in the Wazuh server cluster. Its purpose is to ensure that agent-group information stored on the master node is replicated in the databases of all worker nodes. The communication is initiated by the master node and follows these stages:
When there is new agent-groups information, the master node sends a JSON string with it to each worker node. This is done only once per worker node.
The worker nodes send the received information to their local wazuh-db service, where it is updated.
The worker nodes compare the checksum of their database with the checksum of the master node.
If the checksum has been different for 10 consecutive times, the worker node notifies the master node.
When notified, the master node sends all the agent-groups information to the worker node.
The worker node overwrites its database with the agent-groups information it has received from the master node.
Local agent-groups thread
The local agent-groups thread runs exclusively on the Wazuh server master node. It periodically queries the local wazuh-db service for any new or updated agent-group information since the last execution. The process doesn't repeat until all updated agent-group data has been successfully distributed to every worker node in the cluster.
Local integrity thread
The local integrity thread runs exclusively on the Wazuh server master node. It periodically reads all integrity files and calculates their checksums. Checksum calculation is slow and reduces performance in clusters with many worker nodes, since each worker node requires its own checksum. To optimize performance, this thread calculates the required integrity checksums once and stores them in a global variable that is periodically updated.
Sendsync thread
The sendsync thread is a Wazuh server cluster task executed exclusively on the master node. Although not shown in the workflow diagram, it enables the redirection of messages received from worker nodes to the appropriate master node services.
This mechanism allows agent registration requests to be processed even when agents are configured to connect to a worker node. In such cases, the sendsync thread receives the registration request from the worker node and forwards it to the master node's Authd service.
Distributed API thread
This thread isn't shown in the schema either. It runs in both master and worker nodes since it is independent of the node type. It is used to receive API requests and forward them to the most suitable node to process the request. The operation of this thread will be explained in later sections.
Code structure
The cluster is built on top of asyncio.Protocol. This Python framework helps us to develop asynchronous communication protocols by just defining a few functions:
connection_made: Defines what to do when a client connects to a Wazuh server and when the Wazuh server receives a new connection.connection_lost: Defines what to do when the connection is closed. It includes an argument containing an exception in case the connection was closed due to an error.data_received: Defines what to do when data is received from the other peers.
The Wazuh cluster protocol is defined on top of this framework. The following diagram shows all Python classes defined based on asyncio.Protocol:
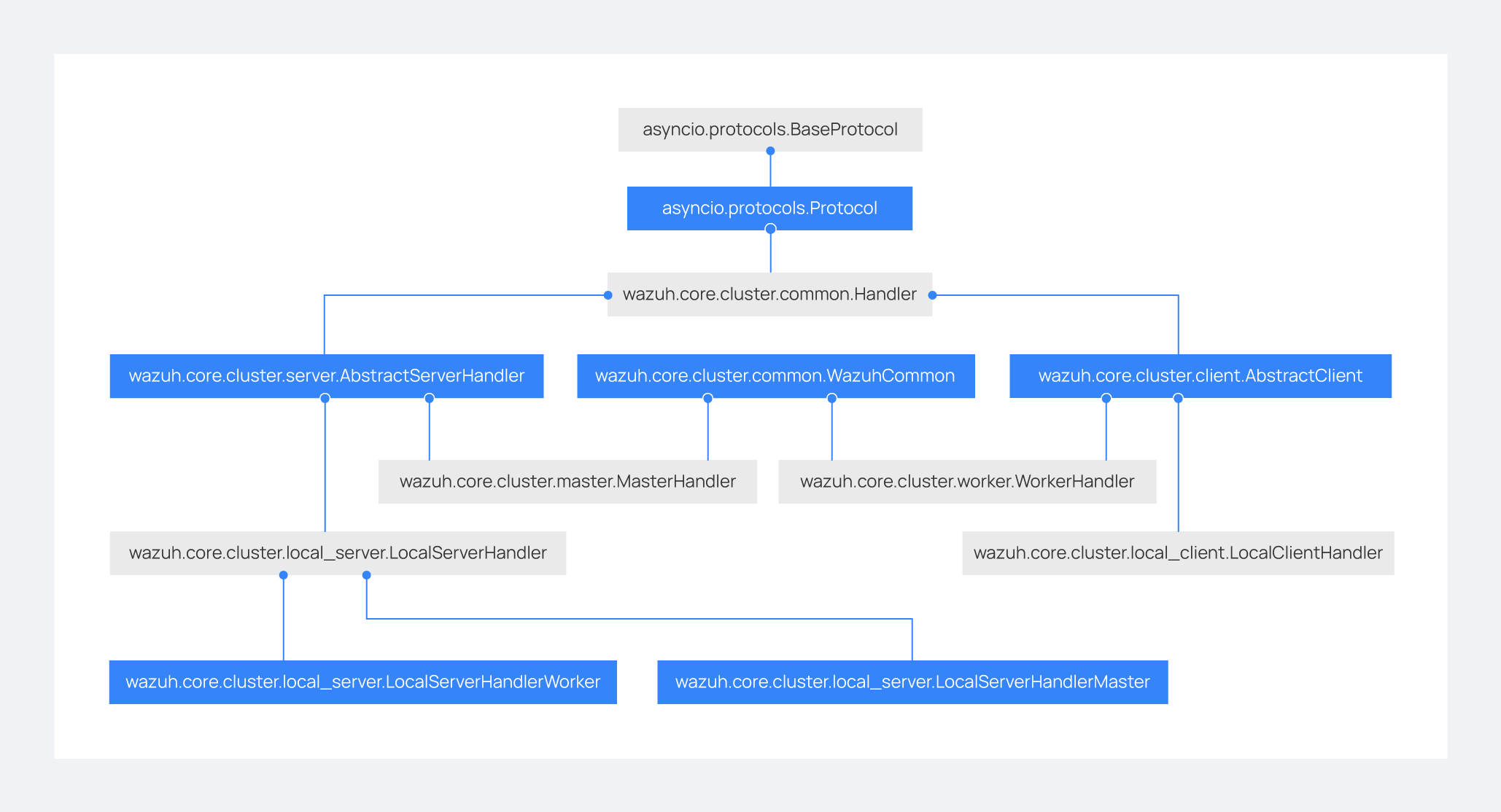
The higher classes on the diagram (wazuh.core.cluster.common.Handler, wazuh.core.cluster.server.AbstractServerHandler, wazuh.core.cluster.common.WazuhCommon, and wazuh.core.cluster.client.AbstractClient) define abstract concepts of what a client and a server is. Those abstract concepts are used by the lower classes on the diagram (wazuh.core.cluster.local_server.LocalServerHandler, wazuh.core.cluster.master.MasterHandler, wazuh.core.cluster.worker.WorkerHandler and wazuh.core.cluster.local_client.LocalClientHandler) to define specific communication protocols. These specific protocols are described in the Protocols section.
There are abstract server and client classes to handle multiple connections from multiple clients and connections to the server. This way, all the logic to connect to a server or to handle multiple clients can be shared between all types of servers and clients in the cluster. These classes are shown in the diagrams below:

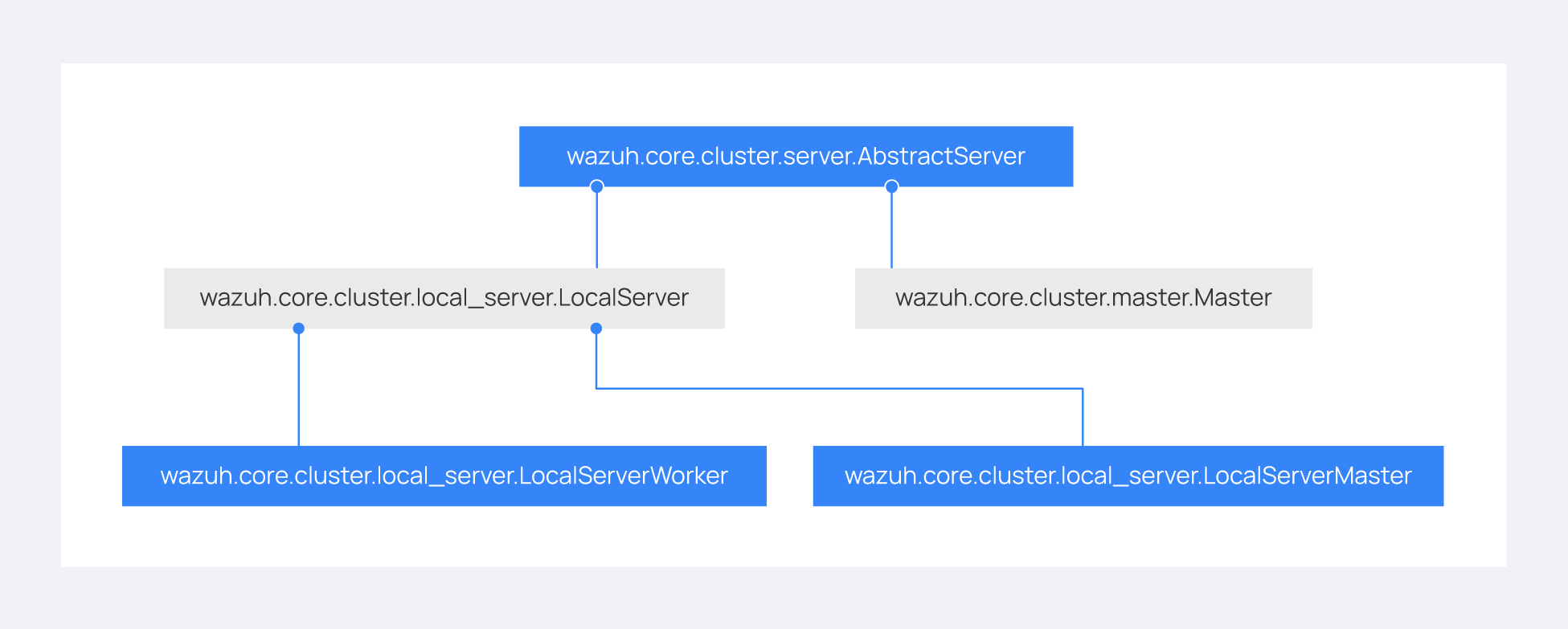
When the wazuh-clusterd process starts in the Wazuh server master node, it creates a Master object. Every time a new Wazuh server worker node connects to the master node, a MasterHandler object is created to handle the connection with that worker node (incoming requests, synchronization processes, etc). This means that there will always be at least a Master object and as many MasterHandler objects to match the number of connected worker nodes. The Master object is responsible for managing all MasterHandler objects created.
When the wazuh-clusterd process starts on the Wazuh server worker node, it creates a Worker object. This object is in charge of initializing worker variables to connect to the master node. A WorkerHandler object is created when connecting to the Wazuh server master node. This object is responsible for sending requests to the master node and managing synchronization processes.
Protocols
Protocol definition
The communication protocol used for all communications (both cluster and API) is defined in wazuh.core.cluster.common.Handler. Each message in the protocol has the following structure:

The protocol message has two parts:
The header: This is usually 22 bytes long. The header has four subparts:
Counter: It specifies the message ID. This is randomly generated for every new sent request. It is very useful when receiving a response, so it indicates which sent request it is replying to.
Payload length: It specifies the amount of data contained in the message payload. It is used to know how much data to expect to receive.
Command: It specifies the protocol message. This string will always be 11 characters long. If the command is not 11 characters long, a padding of
-is added until the string reaches the expected length. All available commands in the protocol are shown below.Flag message divided: This specifies whether the message has been divided depending on if the initial payload length was more than 5242880 bytes or not. The flag value can be
dif the message is a divided one, or nothing if the message is the end of a divided message or a single message.
The payload: This will be 5242880 bytes long at maximum.
Wazuh cluster protocol
This communication protocol is used by all Wazuh server cluster nodes to synchronize information required to receive reports from the Wazuh agents. All communications are made through TCP. These commands are defined in wazuh.core.cluster.master.MasterHandler.process_request and in wazuh.core.cluster.worker.WorkerHandler.process_request.
Message |
Received in |
Arguments |
Description |
|---|---|---|---|
|
Master |
|
First message sent by a worker node to the master node on first connection. |
|
Master |
None |
Ask permission to start synchronization protocol. Message characters define the action to do:
|
|
Master |
None or String ID<str> |
Start synchronization protocol. Message characters define the action to do:
|
|
Master |
None or String ID<str> |
End synchronization protocol. Message characters define the action to do:
|
|
Worker |
Agent-groups data <dict> |
Start synchronization protocol. Message characters define the action to do:
|
|
Master |
Error msg<str> |
Notify an error during synchronization. Message characters define the action to do:
|
|
Master |
Arguments<Dict> |
Receive a message from a worker node destined for the specified daemon on the master node. |
|
Worker |
|
Notify the |
|
Both |
|
Notify errors in the |
|
Master |
Arguments<Dict> |
Request sent from |
|
Master |
Arguments<Dict> |
Request sent from |
|
Master |
Arguments<Dict> |
Receive an API call related to cluster information. This gets node information or healthcheck. |
|
Both |
|
Receive a distributed API request. If the API call has been forwarded multiple times,
the sender node contains multiple names separated by a |
|
Both |
|
Receive a distributed API response from a previously forwarded request. Responses are sent using send long strings protocol so this request only needs the string ID. |
|
Both |
|
Receive an error related to a previously requested distributed API request. |
|
Worker |
None |
The master node verifies that the worker node integrity is correct. |
|
Worker |
None |
The master node will send the worker node integrity files to update. |
|
Worker |
|
Master node has finished sending integrity files. The files were received in the task name
previously created by the worker node in |
|
Worker |
Arguments<Dict> |
Master node has finished updating agent-info. Number of updated chunks and chunks with errors (if any) will be sent. |
|
Worker |
Error msg<str> |
Notify an error during agent-info synchronization. |
Local protocol
This communication protocol is used by the Wazuh server API to forward requests to other Wazuh server cluster nodes. All communications are made using a Unix socket since the communication is local (from the process running the API to the process running the cluster). These commands are defined in wazuh.core.cluster.local_server.LocalServerHandler.process_request, wazuh.core.cluster.local_server.LocalServerHandlerMaster.process_request and wazuh.core.cluster.local_server.LocalServerHandlerWorker.process_request.
Message |
Received in |
Arguments |
Description |
|---|---|---|---|
|
Both |
None |
Returns active cluster configuration. Necessary for active configuration API calls. |
|
Both |
Arguments<Dict> |
Request sent from |
|
Both |
Arguments<Dict> |
Request sent from |
|
Both |
None |
Receive a request to obtain custom ruleset files and their hashes. |
|
Both |
Filepath <str>, Node name <str> |
Request used to test send file protocol. Node name parameter is ignored in worker nodes (it is always sent to the master node). |
|
Both |
Arguments<Dict> |
Receive a distributed API request from the API. When this request is received in a worker node it is forwarded to the master node and executed locally on the master node. |
|
Server |
Node name <str>, Arguments <Dict> |
Forward a distributed API request to the specified node.
To forward the request to all nodes, use |
Common messages
All cluster communication protocols are built on a shared abstract base. This base layer defines the core messages used to manage connections, exchange keep-alive signals, and perform other essential cluster operations. These message-handling commands are implemented in the following modules: wazuh.core.cluster.common.Handler.process_request, wazuh.core.cluster.server.AbstractServerHandler.process_request and wazuh.core.cluster.client.AbstractClient.process_request.
Message |
Received in |
Arguments |
Description |
|---|---|---|---|
|
Both |
String length <int> |
Used to start the sending long strings process. |
|
Both |
String Id <str>, Data chunk <str> |
Used to send a string chunk during the sending long strings process. |
|
Both |
String length <int> |
Used to notify an error while sending a string so that the reserved space is freed. |
|
Both |
Filename <str> |
Used to start the sending file process. |
|
Both |
Filename <str>, Data chunk <str> |
Used to send a file chunk during the sending file process. |
|
Both |
Filename <str>, File checksum <str> |
Used to finish the sending file process. |
|
Both |
Task name <str>, Error msg <str> |
Used to cancel the task in progress on the sending node. |
|
Both |
Message <str> |
Used to send keepalives to the peer. Replies with the same received message. |
|
Server |
Message <str> |
Used by the client to send keepalives to the server. |
|
Client |
Message <str> |
Used by the server to send keepalives to the client. |
|
Server |
Client name <str> |
First message sent by a client to the server on its first connection. The Wazuh protocol modifies this command to add extra arguments. |
Cluster performance
Asynchronous tasks
A key factor contributing to the performance of the Wazuh server cluster is the use of asynchronous tasks. Similar to threads in Python, asynchronous tasks run concurrently with the main process and other tasks, but they are significantly more lightweight and faster to create. Their efficiency comes from leveraging the latency of I/O operations. This means that while one task is waiting for data to be transmitted or received through a socket, another can continue executing.
Each of the threads described in the Workflow section are implemented as asynchronous tasks. These tasks are started in wazuh.core.cluster.client.AbstractClientManager.start, wazuh.core.cluster.server.AbstractServer.start, and wazuh.core.cluster.local_server.LocalServer.start and they are all implemented using infinite loops.
In addition to the tasks already described, additional tasks are created whenever an incoming request requires more complex processing. These tasks are instantiated specifically to handle the request and are terminated once the corresponding response has been sent. This architectural approach ensures that the server is not blocked by a single request and can continue serving others efficiently.
One such task, implemented as a class, is responsible for receiving and processing files from a peer. An instance of this class is created at the start of a synchronization process and is destroyed once the process is complete. Internally, it launches an asynchronous task that remains active until all files required for synchronization have been successfully received. This asynchronous task has a callback that checks if there was an error during the synchronization process.

Multiprocessing
Asynchronous tasks are suitable for optimizing workloads and reducing I/O wait times but are unsuitable for CPU-intensive tasks because of Python's execution model. Python allows a single thread to take control of the Python interpreter through the Global Interpreter Lock (GIL). Therefore, asynchronous tasks run concurrently and not in parallel. Following the analogy of the previous section, it is as if there is effectively only one chef who has to do all the tasks. The chef can only do one at a time so if one task requires all his/her attention, the other ones are delayed.
The master node in the Wazuh server cluster executes a heavy workload, especially in large environments. Although the tasks are asynchronous, they have sections that require high CPU usage, such as calculating the hash of the files to be synchronized with the Local integrity thread. To avoid other tasks from waiting for the Python interpreter to complete the CPU-bound parts, multiprocessing is used. Using the same analogy again, multiprocessing would be equivalent to having more chefs working in the same kitchen.
Multiprocessing is implemented in the cluster process of both the Wazuh server master node and the worker nodes, and the concurrent.futures.ProcessPoolExecutor is used for this purpose. Cluster tasks can use any available process in the pool to delegate and run in parallel, the parts of their logic that are CPU intensive. With this, it is possible to take advantage of more CPU cores and increase the overall performance of the cluster process. When combined with asyncio, best results are obtained.
Child processes are created when the parent wazuh-clusterd starts. They stay in the process pool waiting for new jobs to be assigned to them. There are two child processes by default within the master node pool. This value can be changed in the process_pool_size variable in the cluster.json file. The worker nodes, on the other hand, create a single child process and this number is not modifiable. The tasks that use multiprocessing in the cluster are the following.
Master node
Local integrity thread: This calculates the hash of all the files to be synchronized. This requires high CPU usage.
Agent info thread: A section of this task sends all the Wazuh agent information to the wazuh-db. The communication is done in small chunks so as not to saturate the service socket. This turned this task into a somewhat slow process and not a good candidate for asyncio.
Integrity thread: Compressing files, which is done inside this task, is fully synchronous and can block the parent cluster process.
Worker nodes
Integrity thread: This is the only task in the Wazuh server worker nodes that uses multiprocessing. It carries out the following CPU intensive actions:
Hash calculation: This calculates the hash of all the files to be synchronized every time Integrity check is started.
Unzip files: This extracts files and can take too long when the zip is large.
Process master files: This processes and moves all the files that were received from the Wazuh server master node to the appropriate destination.
Below is an example diagram of how the process pool is used in the Wazuh server master node:
Integrity synchronization process
This section explains the integrity synchronization process and how asyncio tasks are created to handle data exchanged with the peer. The diagram below outlines the complete workflow involved in integrity synchronization:
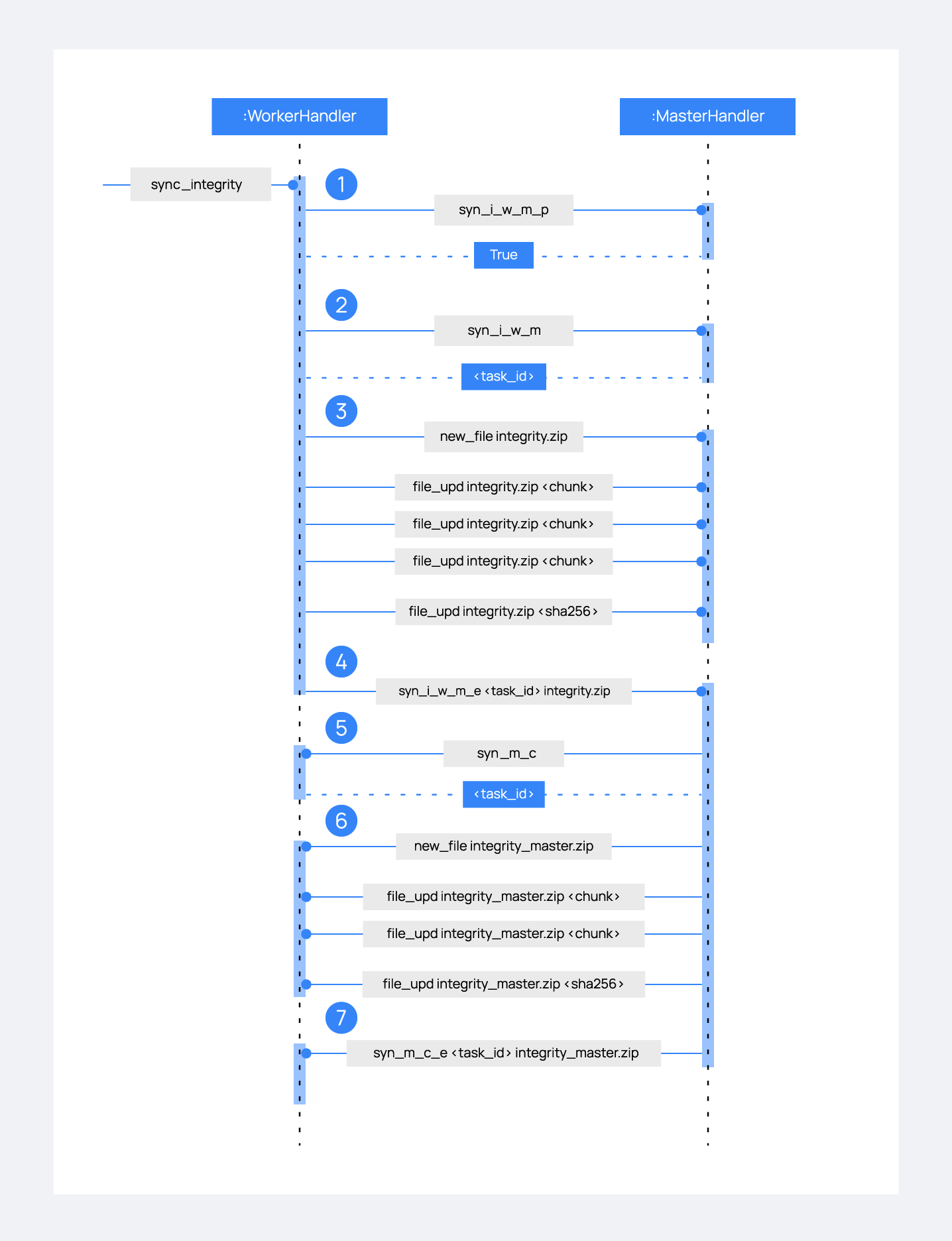
1: The
sync_integritytask on the worker wakes up after sleeping during interval seconds (which is defined in the cluster.json file). The first thing it does is checking whether the previous synchronization process is finished or not using thesyn_i_w_m_pcommand. The master replies with a boolean value specifying that the previous synchronization process is finished, and the worker can start a new one.2: The worker starts the synchronization process using the
syn_i_w_mcommand. When the master receives the command, it creates an asyncio task to process the received integrity from the worker. But since no file has been received yet, the task keeps waiting until the worker sends the file. The master sends the worker the task ID so the worker can notify the master to wake it up once the file has been sent.3: The worker node starts the sending file process. Which has three steps:
new_file,file_updandfile_end.4: The worker notifies the master that the integrity file has already been sent. At that moment, the master wakes the previously created task up and compares the worker files with its own. In this example the master finds out the worker's integrity is outdated.
5: The master starts a sync integrity process with the worker using the
syn_m_ccommand. The worker creates a task to process the integrity received from the master, but the task is sleeping since it has not been received yet. This is the same process the worker has done with the master but changing directions.6: The master sends all information to the worker through the sending file process.
7: The master notifies the worker that the integrity information has already been sent using the
syn_m_c_ecommand. The worker wakes the previously created task up to process and update the required files.
To sum up, asynchronous tasks are created only when the received request needs to wait for some data to be available (for example, synchronization tasks waiting for the zip file from the other peer). If the request can be solved instantly, no asynchronous tasks are created for it.
Distributed API requests
Another example that can show how asynchronous tasks are used is Distributed API requests. Before explaining the example, we review the different type of requests that can be done in the distributed API:
local_any: The request can be solved by any Wazuh server node. These requests are usually information that the Wazuh server master node distributes to all nodes such as rules, decoders or CDB lists. These requests will never be forwarded or solved remotely.local_master: The request can be solved by the Wazuh server master node. These requests are usually information about the global status and management of the cluster such as agent information/status/management, agent groups management, cluster information, etc.distributed_master: The Wazuh server master node must forward the request to the most suitable node to solve it.
The type association with every endpoint can be found here: API controllers.
Imagine a Wazuh server cluster with two nodes, where there is an agent reporting to the worker node with ID: 020. The following diagram shows the process of running a distributed API request by requesting the GET/sca/020 API endpoint:
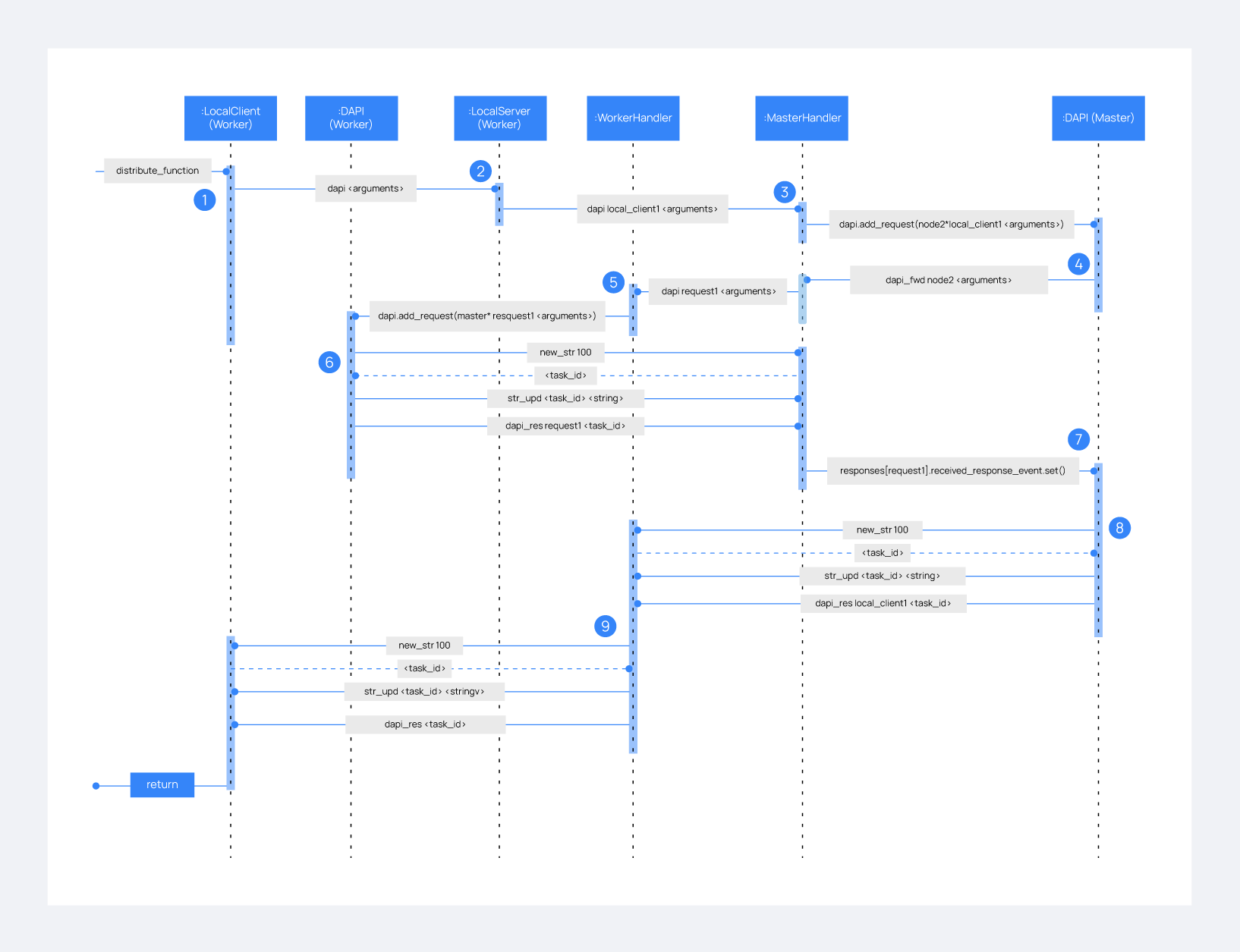
1: The user does an API request. The API server receives the connection and calls
distribute_function. Since the requested endpoint isdistributed_masterthe worker node realizes it can't solve the request locally and proceeds to forward the request to the master node.2: The API server doesn't have direct contact with the Wazuh server cluster master node. So the API process forwards the request to a Unix socket, because the cluster has to receive API requests locally. This Unix server is running inside the cluster process, so it can send requests to the master node. In order to identify the API request when the master node sends a response back, the local server adds an ID (
local_client1in this example).3: When the master node receives the API request, it is added to a queue where all pending requests from all nodes are stored. Since this queue is shared with all other nodes, the master node adds the node ID to the request (
node2in this example).4: The master node pops the received request out of its queue. It then realizes that agent 020 is reporting in the worker node
node2, so it forwards the request tonode2. This is because the master node is the one with the most updated information about the agent.5: The master node creates a new request to get the necessary information from the worker node. This request includes a new ID (
request1in the example) so the master can identify the response when the worker sends it. The original request sent by the worker node remains in the master node awaiting to be solved.6: The worker node receives the request from the master node and adds it to its request queue. The worker solves the request locally and sends the request response to the master using the long string process. Once the response has been sent, the worker notifies the master using the
dapi_rescommand. Thetask_idis necessary since the master can receive multiple long strings at the same time and it needs a way to identify each one.7: Once the master node receives the required information from the worker node, it is able to solve the originally received request from the worker node. The master node notifies the distributed API that the response has already been received.
8: The master node uses the long string process to send the response to the worker node.
9: The worker node receives the response from the master node and starts a new send long string process to forward it to the API process. Once the API receives the response over the Unix socket connection it had with the cluster process, the response is returned to the user.
In summary, asynchronous tasks are created to forward requests from one node to the other, enabling Wazuh server nodes to be available to receive new requests. None of the objects shown in the diagram remain blocked waiting for a response, they just wait to be notified when the response is available. That is achieved using Events.
Why is it necessary to forward the request to the master node if the agent was reporting to the worker node where the request was originally done? The worker nodes do not have a global vision of the cluster state. If an agent switches from one cluster node to another, worker nodes remain unaware of the change because they are not notified about it.
Only the master receives the agent-info data from all worker nodes. It is the only cluster node that knows where an agent is really reporting. This is why all API requests are always forwarded to the master node, except the local_any ones.
Troubleshooting
The Wazuh server cluster has different components working together including; a network protocol, input/output (I/O) and some Wazuh specific logic. All these components log their progress in logs/cluster.log file. To make things easier for developers, each component includes a log tag to help developers see which exact component logged the event. The following is an example of how the log file looks:
2021/03/29 07:05:26 INFO: [Worker worker1] [Integrity check] Starting. Received metadata of 12 files.
2021/03/29 07:05:26 INFO: [Worker worker1] [Integrity check] Finished in 0.016s. Sync required.
2021/03/29 07:05:26 INFO: [Worker worker1] [Integrity sync] Starting.
2021/03/29 07:05:26 INFO: [Worker worker1] [Integrity sync] Files to create in worker: 0 | Files to update in worker: 0 | Files to delete in worker: 1 | Files to receive: 0
2021/03/29 07:05:26 INFO: [Worker worker1] [Integrity sync] Finished in 0.015838s.
2021/03/29 07:05:27 INFO: [Master] [Local integrity] Starting.
2021/03/29 07:05:27 INFO: [Master] [Local integrity] Finished in 0.013s. Calculated metadata of 11 files.
2021/03/29 07:05:27 INFO: [Worker worker1] [Agent-info sync] Starting.
2021/03/29 07:05:27 INFO: [Worker worker1] [Agent-info sync] Finished in 0.001s (0 chunks received).
2021/03/29 07:05:31 INFO: [Master] [D API] Receiving request: check_user_master from worker1 (237771)
When an error occurs in the cluster, it appears in the logs under the ERROR: tag. A good first step when troubleshooting cluster issues is to check the following:
# grep -i error /var/ossec/logs/cluster.log
2019/04/10 15:37:58 wazuh-clusterd: ERROR: [Cluster] [Main] Could not get checksum of file client.keys: [Errno 13] Permission denied: '/var/ossec/etc/client.keys'
If the error log message doesn't provide enough detail to identify the issue, you can enable traceback logging by setting the log level to DEBUG2. To do this, run the following command:
# sed -i "s:wazuh_clusterd.debug=1:wazuh_clusterd.debug=2:g" /var/ossec/etc/internal_options.conf
# systemctl restart wazuh-manager
# grep -i error /var/ossec/logs/cluster.log -A 10
2019/04/10 15:50:37 wazuh-clusterd: ERROR: [Cluster] [Main] Could not get checksum of file client.keys: [Errno 13] Permission denied: '/var/ossec/etc/client.keys'
Traceback (most recent call last):
File "/var/ossec/framework/python/lib/python3.9/site-packages/wazuh-4.14.6-py3.7.egg/wazuh/core/cluster/cluster.py", line 217, in walk_dir
entry_metadata['blake2b'] = blake2b(os.path.join(common.ossec_path, full_path))
File "/var/ossec/framework/python/lib/python3.9/site-packages/wazuh-4.14.6-py3.7.egg/wazuh/core/utils.py", line 555, in blake2b
with open(fname, "rb") as f:
PermissionError: [Errno 13] Permission denied: '/var/ossec/etc/client.keys'
Having the traceback usually helps to understand what is happening.
There are two ways of configuring the log level:
Modifying the
wazuh_clusterd.debugvariable in theinternal_options.conffile.Using the argument
-din thewazuh-clusterdbinary.